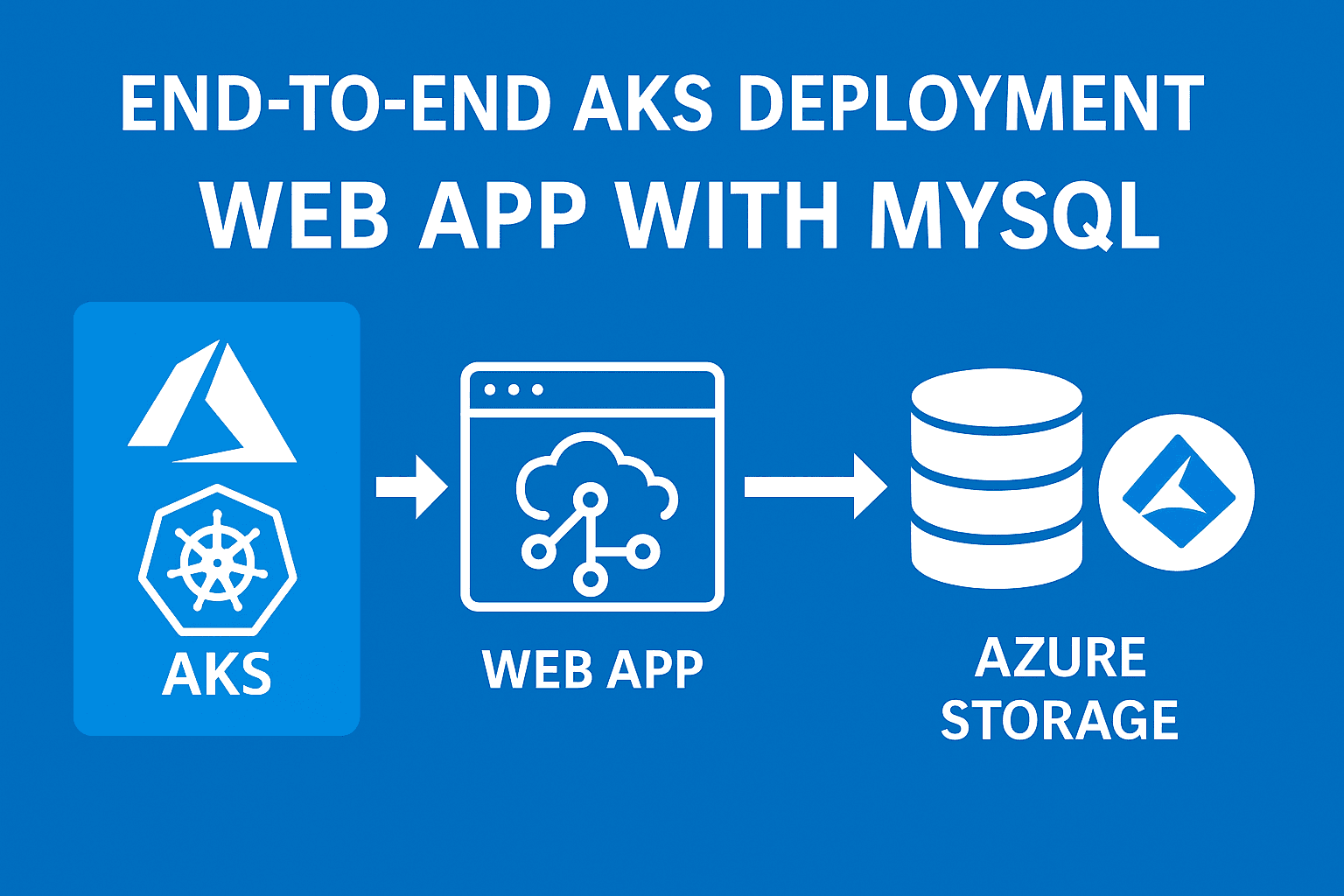
Multi-tier WebApp Deployment Migration to AWS
Multi-tier web application stack Re-architect services for AWS | ElasticBeanstalk, Amazon MQ, Elastic Cache, Aurora, CloudFront
Passionate about helping organizations build scalable infrastructure and DevOps solutions with cloud technologies. Experienced in designing robust systems, automating processes, and driving efficiency through innovative cloud solutions. Advocate for best practices in DevOps and cloud computing, committed to enabling teams to achieve their full potential.
Project Overview & Architecture
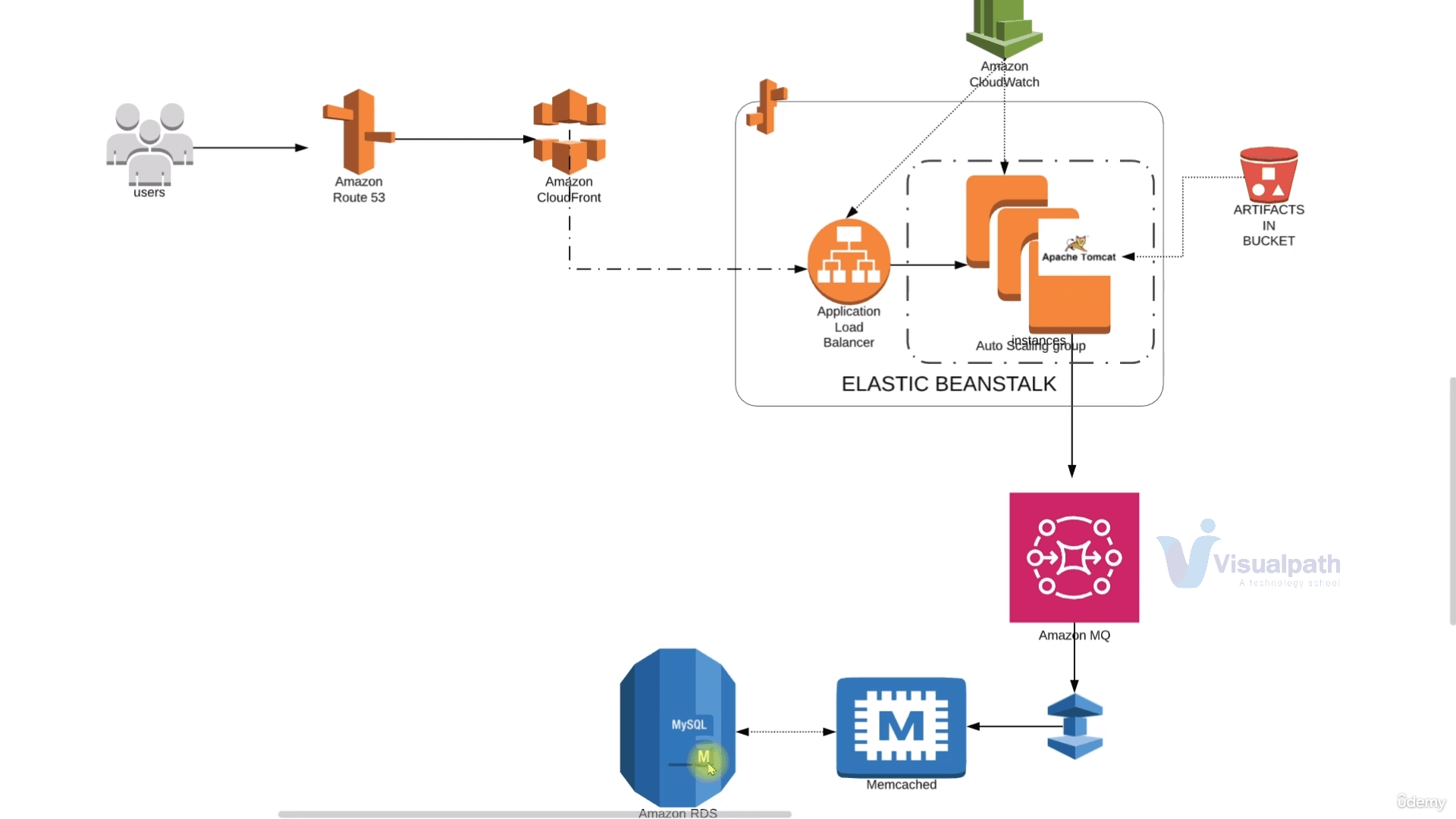
In this project, we'll re-architect the multi-tier application deployment stack with AWS Services.
All the services such as EC2, MySQL, Memcached, RabbitMQ and Tomcat, etc.. will be replaced by respective AWS-Managed Services.
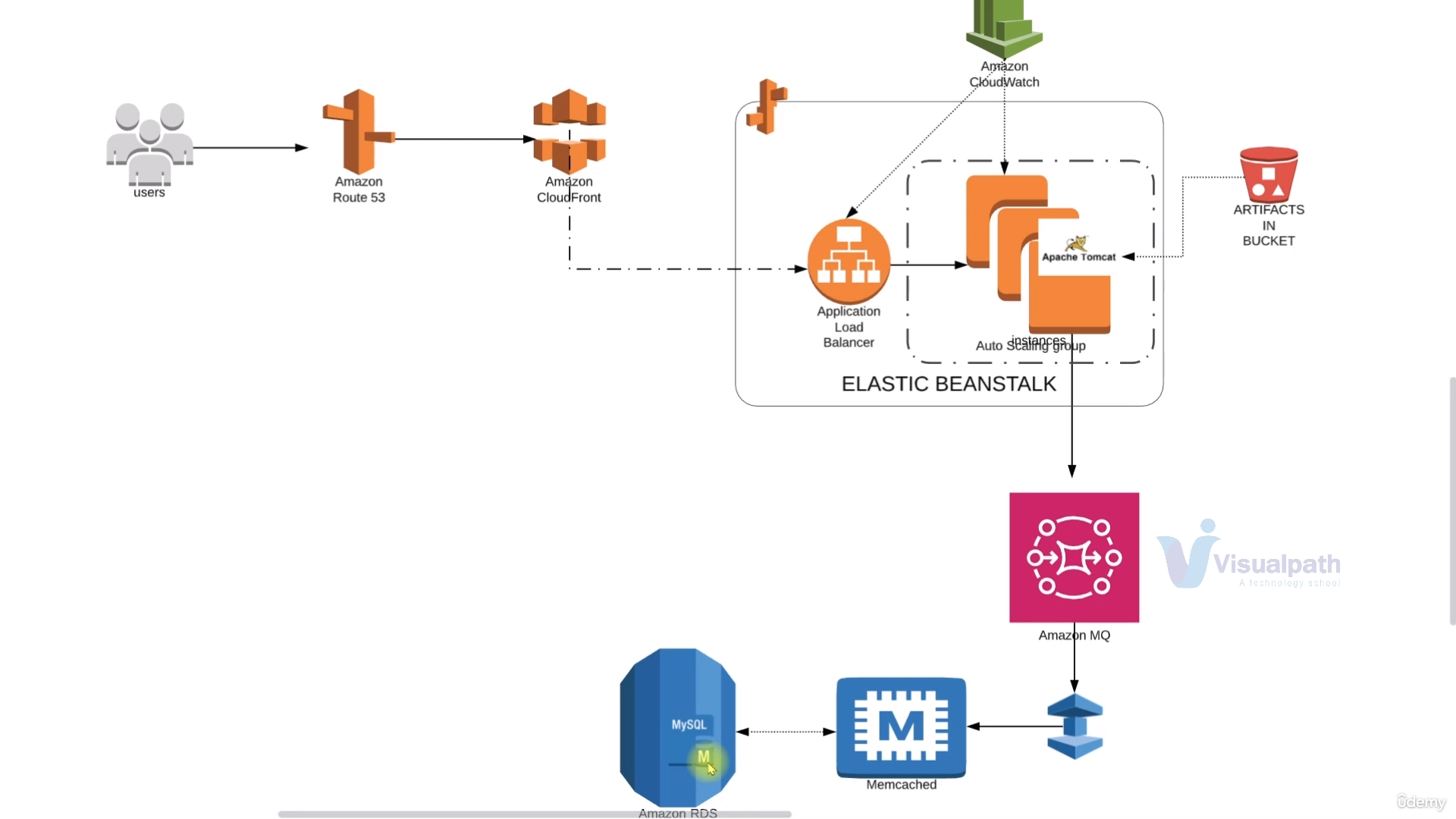
Here, the user will hit the URL which will be routed to and from the Route53 DNS service. This Route53 will be configured with the Amazon CloudFront URL and when the user request comes to Route53 DNS it will redirect it to CloudFront(the CDN service)
The request will further be redirected to the Application Load Balancer which is managed by Beanstalk.
The load balancer will further forward the traffic to the instances in AutoScaling Group which are also managed by Beanstalk itself.
For backend services, the request will further access Amazon MQ as queuing service which will further take the request to Elastic Cache and RDS.
All these will be monitored by the Amazon CloudWatch
Self-Managed vs AWS Managed Services
Here we'll see a brief explanation of our self-managed services that we implemented previously and their respective AWS-Managed alternatives :
| Self Managed <-- | --> AWS Managed |
| EC2 | Beanstalk |
| MySQL(MariaDB) | RDS Instances |
| Memcached | Elastic Cache |
| RabbitMQ | ActiveMQ |
| Route53 | Route53 |
Beanstalk: Previously we launched EC2 instances to install our services like Tomcat server, MySQL, etc. as well as set up the Autoscaling and Load Balancing(NGINX replacement) for them manually. Now, beanstalk will automate all these tasks. It'll also set up S3 buckets automatically.
MySQL DB: Previously we installed MySQL MariaDB as our database service now, instead we'll use RDS Instances which is a platform as a service. It allows us to choose the database, scaling will be easy, and regular backups are taken.
ActiveMQ: RabbitMQ will be replaced by ActiveMQ as queuing service.
Route 53: It will be used as DNS. we are not replacing it as it is already an AWS-managed service.
CloudFront: It is an AWS-managed content delivery service for a global audience.
Flow of Execution
Create key-pair for Beanstalk Instance login
Create a Security Group for backend services(Elasticache, RDS, Active MQ)
Create RDS
Create Amazon Elastic Cache
Create Amazon Active MQ
Create Elastic Beanstalk Environment
Update the Security Group of backend services to allow traffic from Beabstalk Security Group.
Update SG of the backend for internal traffic.
Lunch an EC2 instance for DB initialization by SSH to RDS DB
Change Healthcheck on Beanstalk to "/login"
Add 443 Https listener to our ELB(Elastic Load Balancer)
NB: ELB will be created by Beanstalk automatically
Build Artifact by providing backend information in
application.propertiesfileDeploy the Artifact to Beanstalk
Create CDN(Content Delivery Network) with SSL Certificate using Amazon CloudFront
Update entry in Godaddy DNS zone
Test the URL.
Step-1(Creating Key-Pair)
Going forward we'll be using Elastic Beanstalk which will take care of launching EC2 instances, ELB etc. However, in some cases, we might need to log in to a particular EC2 instance separately so to be on safer since we are creating Key-pair.
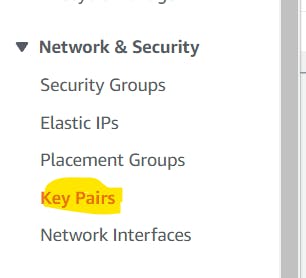
Click on Key Pairs--> Create Key Pair--> Fill in the configuration--> Click on Create Key Pair at the bottom
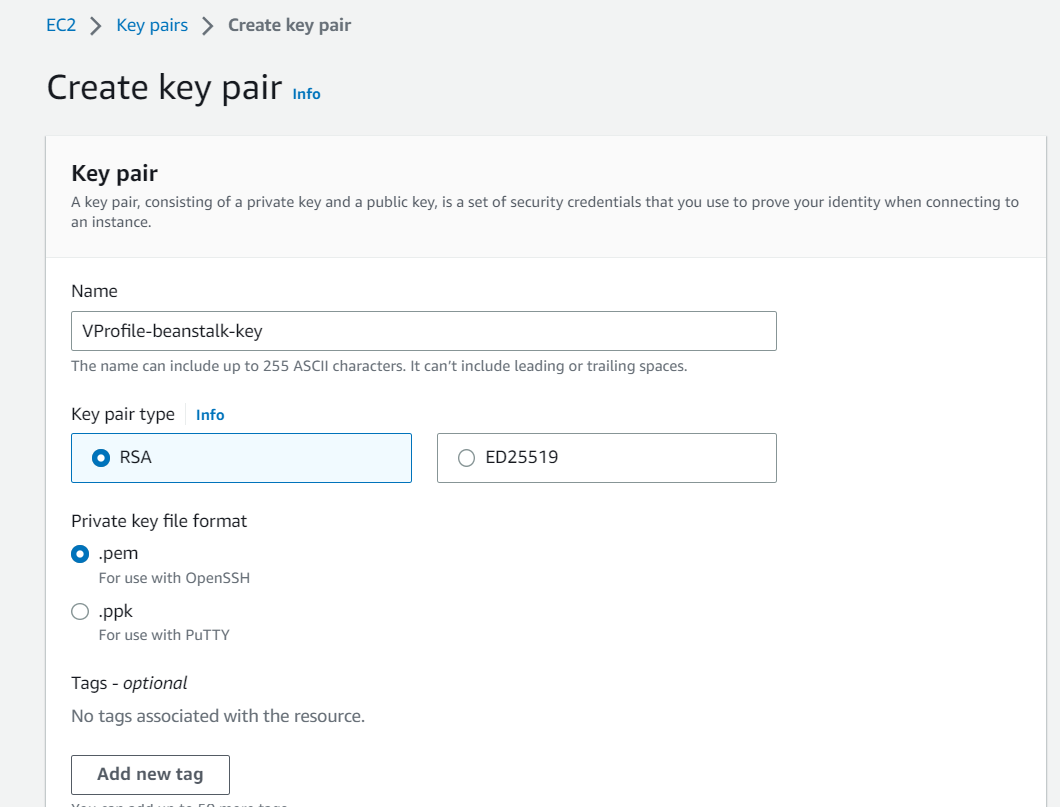
Here I have chosen .pem type as the Key format as I'll be connecting to the instance through GitBash. If you are connecting with Putty you can go with .ppk.
Step-2(Creating SG for Backend Service)
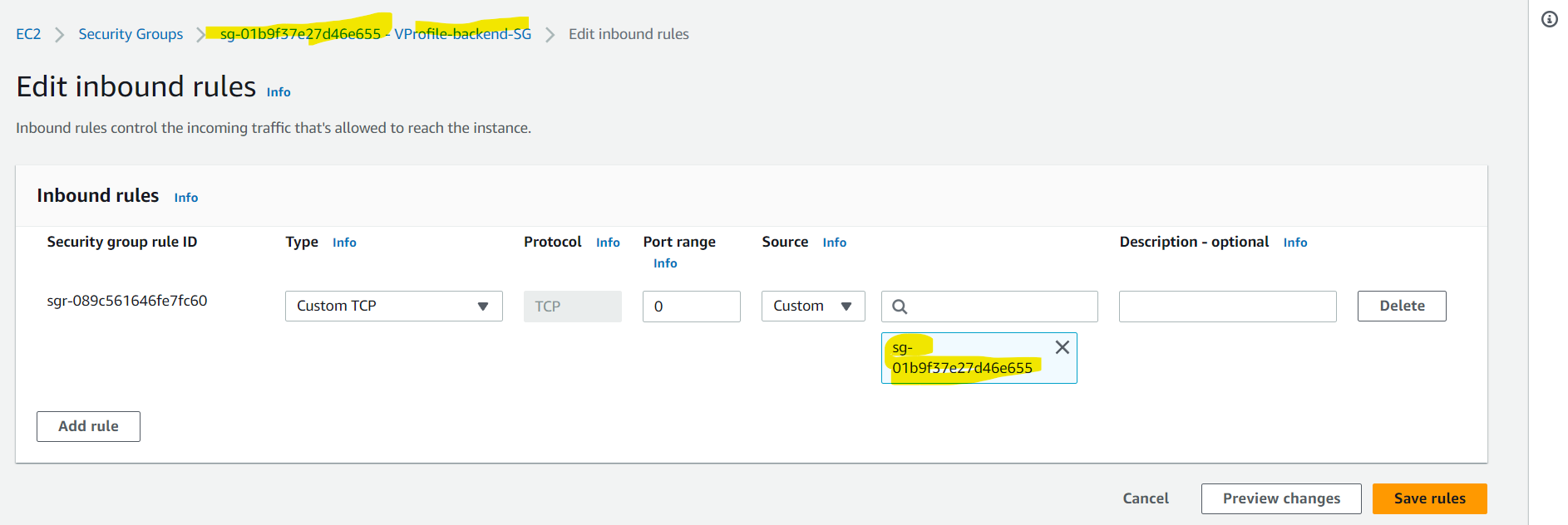
Here we'll be creating a security group named VProfile-backend-SG which will first have access to itself for internal communication. Below you can see that this security group has inbound access only to itself:
Step-3(Setting up RDS)
RDS is an AWS-managed Relational Database Service that provides ample customization, auto-scaling, snapshots, mult AZ for high availability and many more.
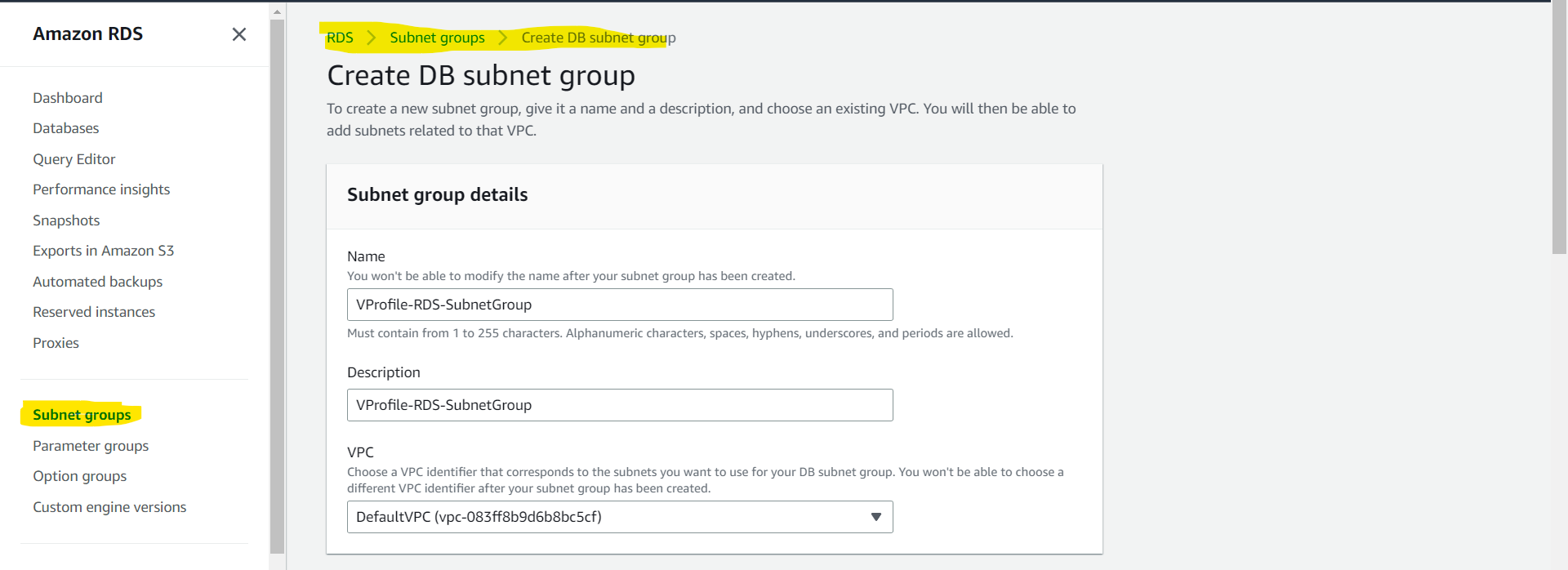
Creating Subnet Group
Before creating the database we need to create a Subnet Group.
Subnet Group: An RDS Subnet Group is a collection of subnets that you can use to designate for your RDS database instance in a VPC. Your VPC must have at least two subnets. These subnets must be in two different Availability Zones in the AWS Region where you want to deploy your DB instance.
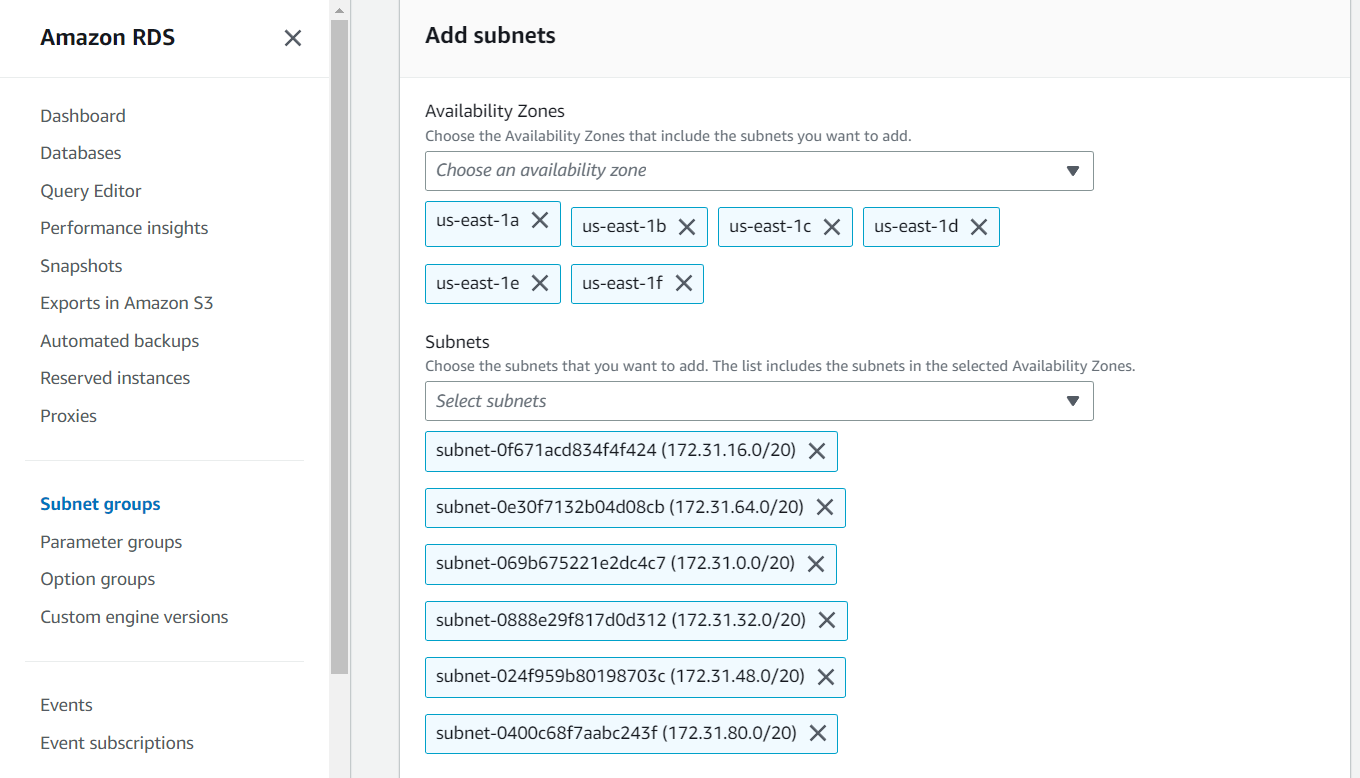
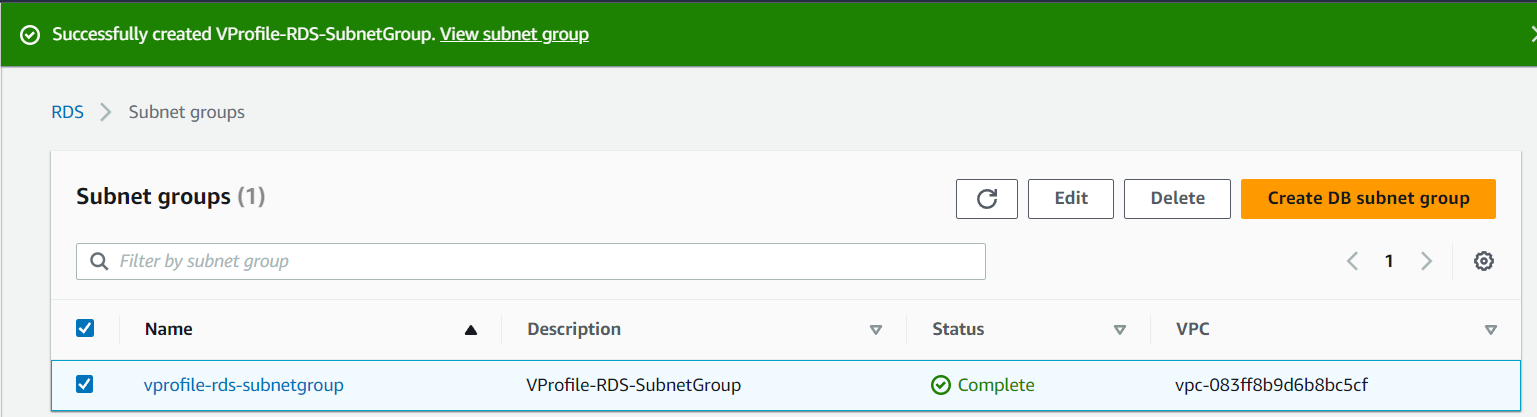
To create the Subnet Group we have made the below configuration where the name of the Subnet Group is vprofile-rds-subnetgroup , VPC is set to default, for Availability Zones we have chosen all the AZs for high availability, our DB instance will be placed in any of these AZs, and also chosen all the Subnets out of all the AZs.
Creating Parameter Groups
Parameter Groups are nothing but the settings or configurations of our database. You manage your database configuration by associating your DB instances and Multi-AZ DB clusters with parameter groups. Amazon RDS defines parameter groups with default settings. It allows us to define our own parameter groups with customized settings.
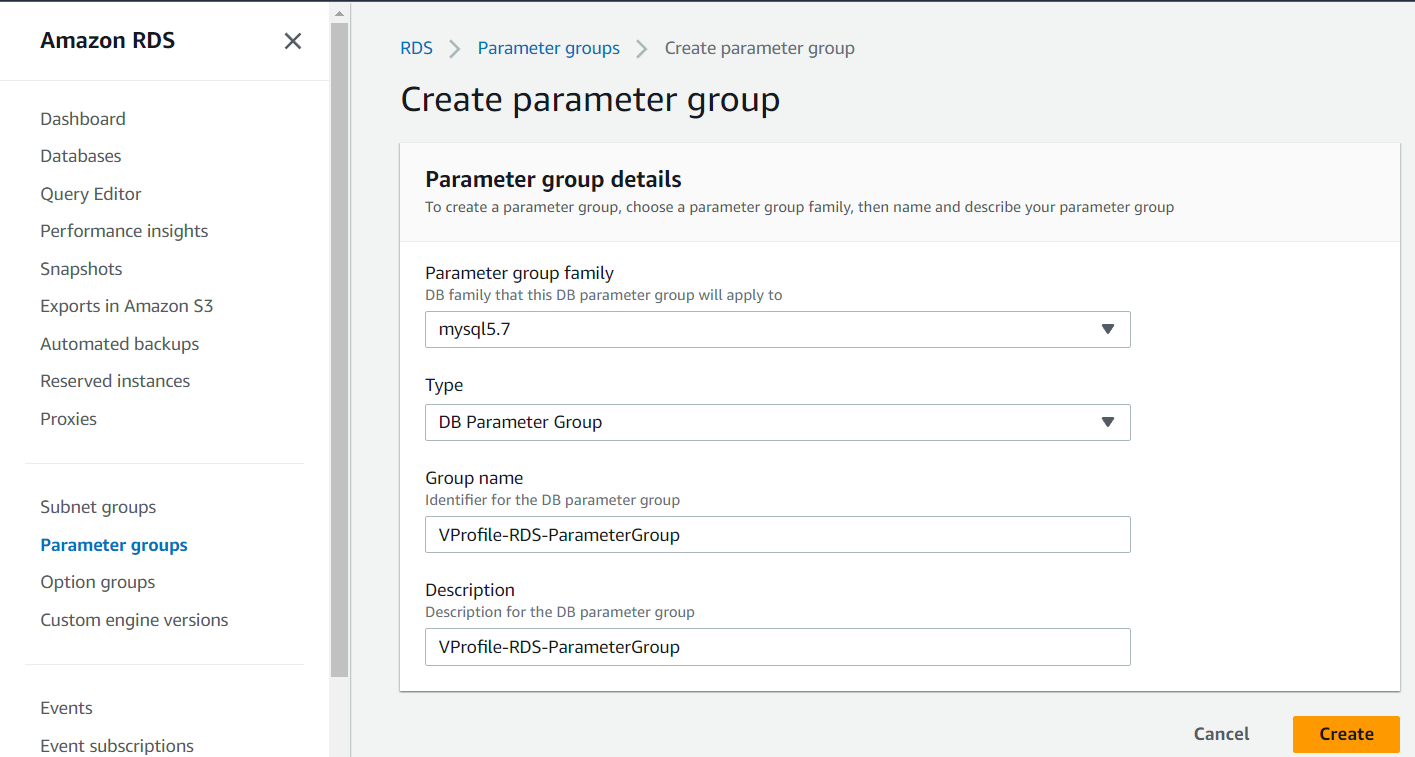
We have created the Parameter Group with the below configurations where we have used mysql5.7 as per our project requirement and the name of the group is VProfile-RDS-ParameterGroup :

Creating Database
Now all the prerequisites have been completed and we can create our database.
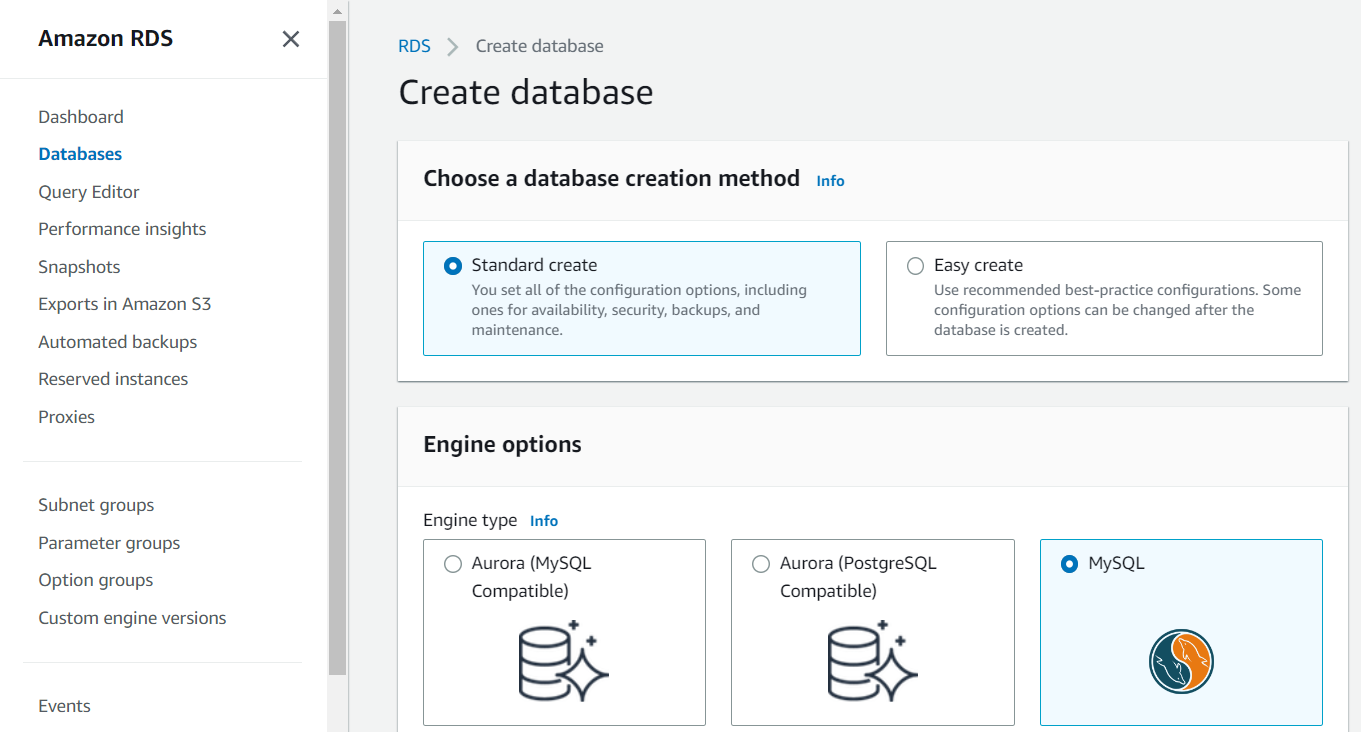
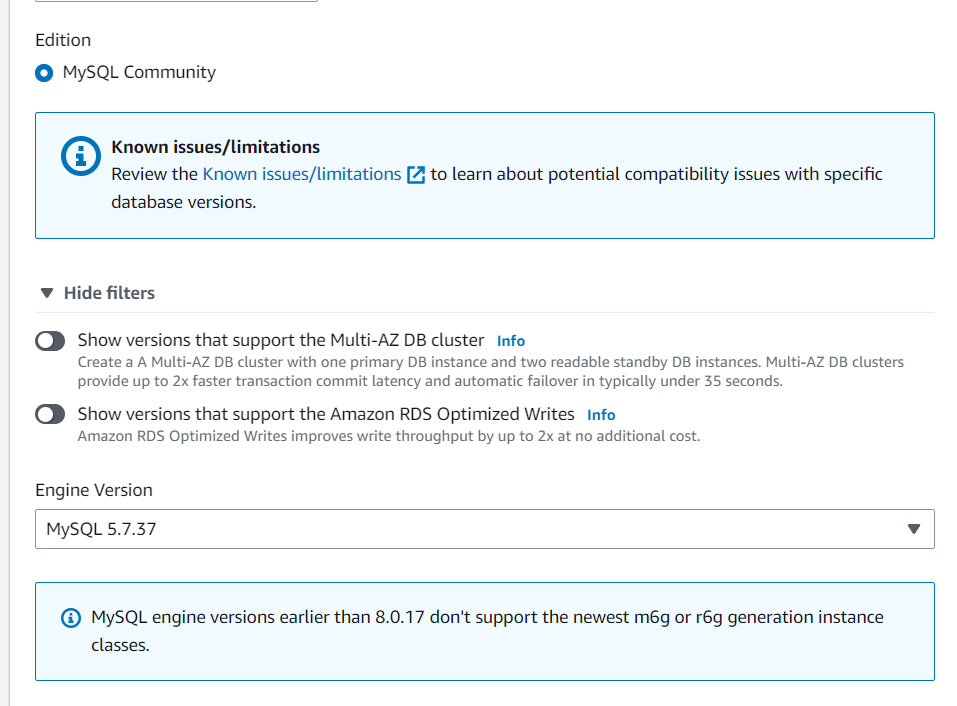
Here, we will go for Standard Create which allows us to customize. And we have chosen MySQL as our DB Engine with MySQL 5.7.37 as per our project
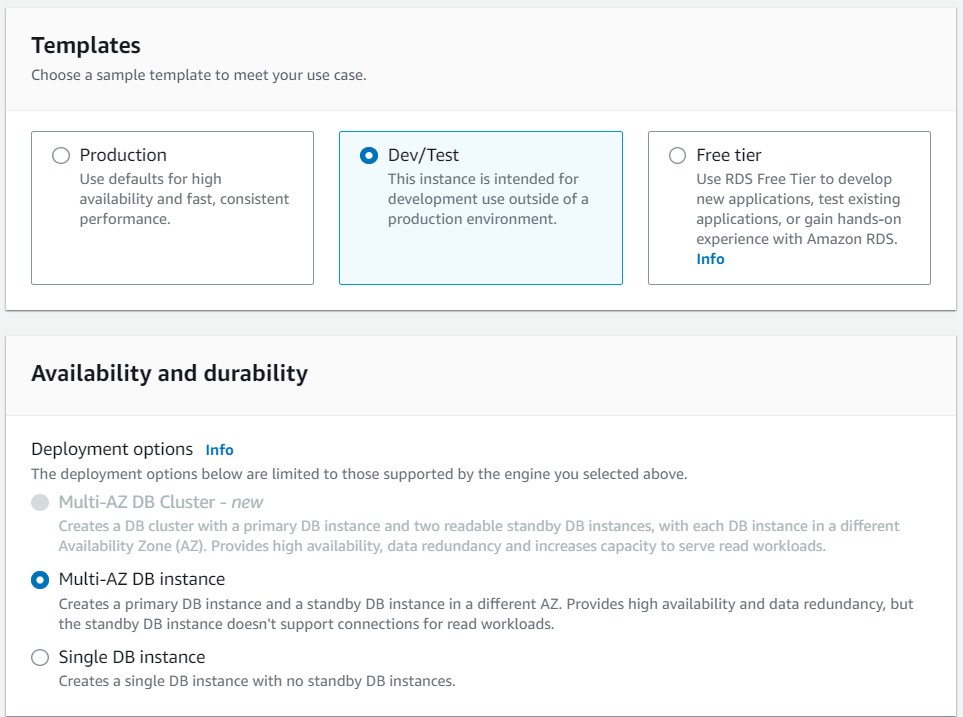
For templates, we have chosen Dev/Test with Multi-AZ DB Instance for high availability. Production template is very expensive and required for large-scale projects.
The setting is as below where the name of the DB is VProfile-MySQL-DB :

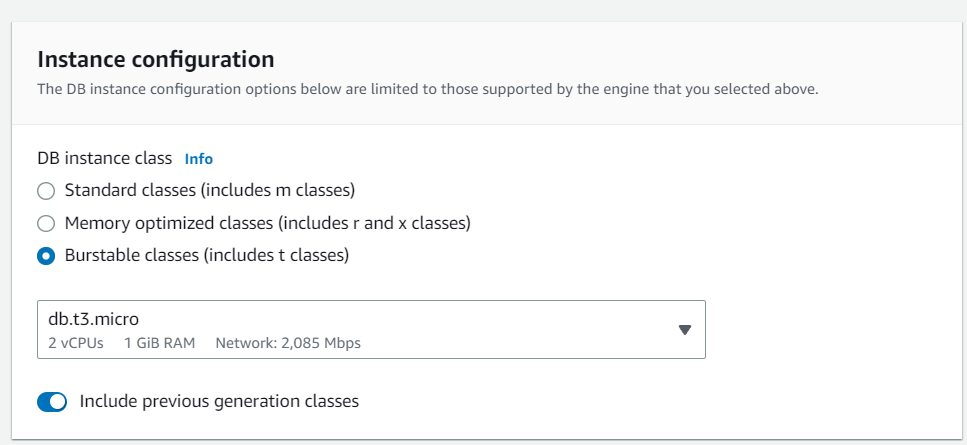
Instance configuration is similar to our regular EC2 configuration we have taken db.t2.micro as it provides 2 CPUs and it is also storage and network optimized:
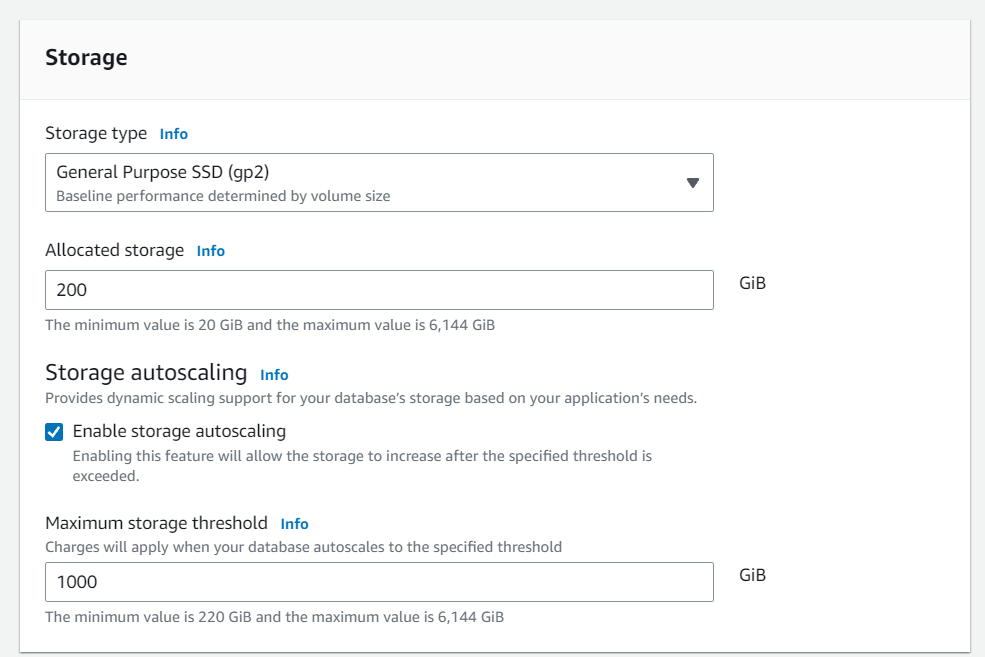
For storage we have Autoscaling enabled:
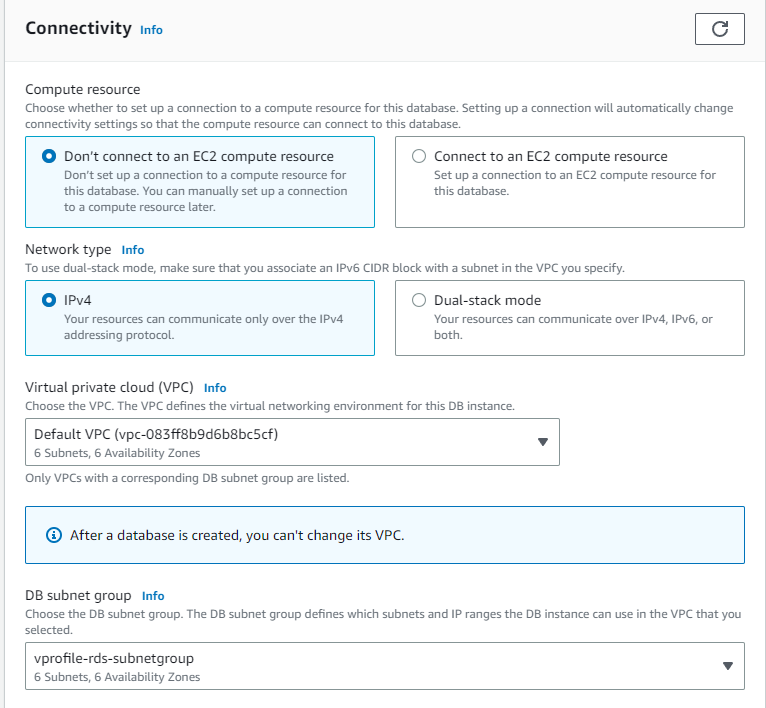
For connectivity, we have selected the default VPC and our vprofile-rds-subnetgroup that we created especially for our DB and this DB is assigned to the existing security group VProfile-backend-SG that we created earlier:
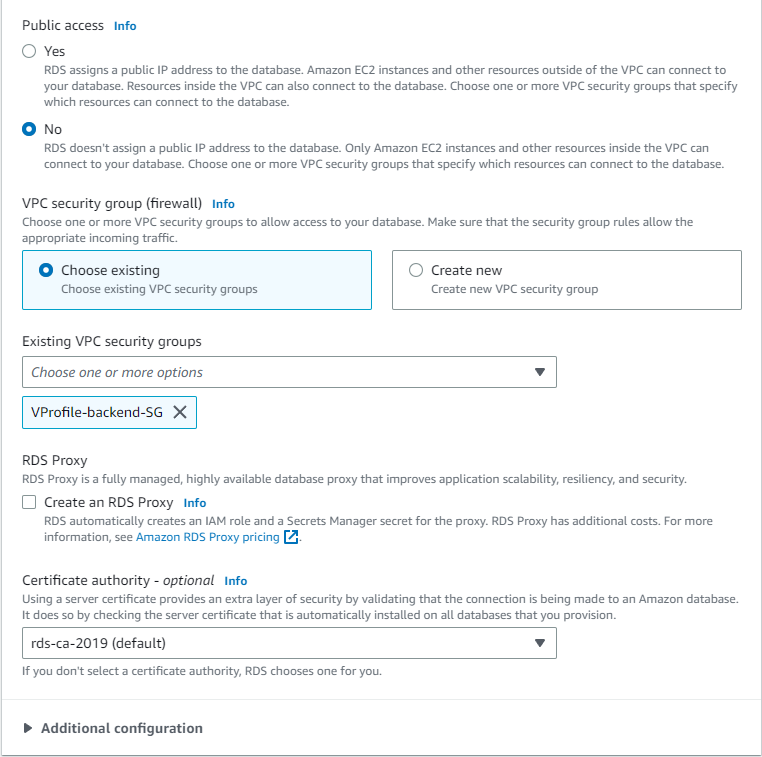
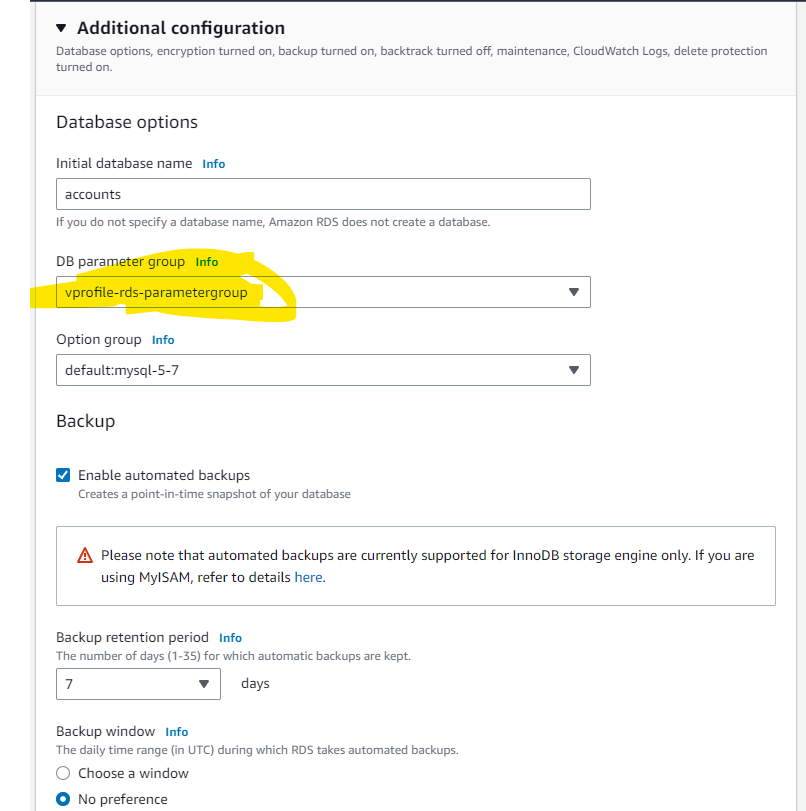
For additional configuration:
Here we are creating an initial database as accounts for our project, the database will be configured according to the DB parameter group vprofile-rds-parametergroup that we created:
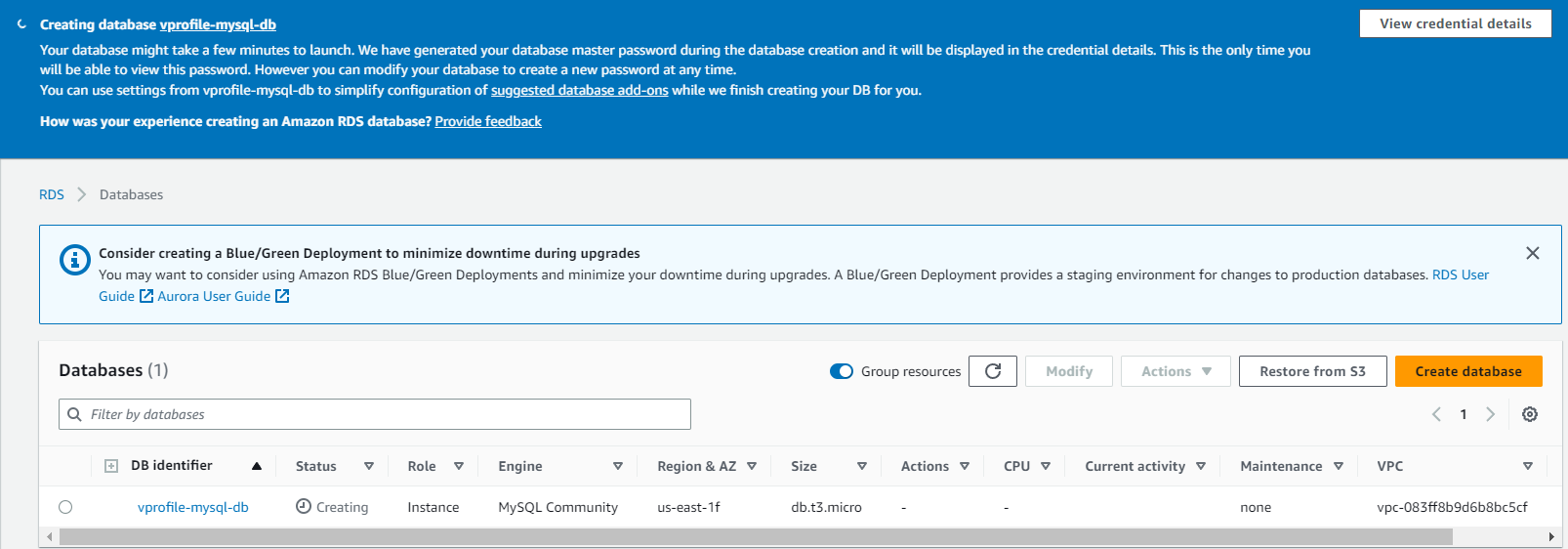
And finally, with the above configuration, create the DB:
Step-4(Setting up ElastiCache)
As discussed earlier, it is one of our backend services that will replace our previous self-managed service Memcached.
For Elastic Cache also, we have to create a Subnet Group and Parameter Group.
Creating Subnet Group
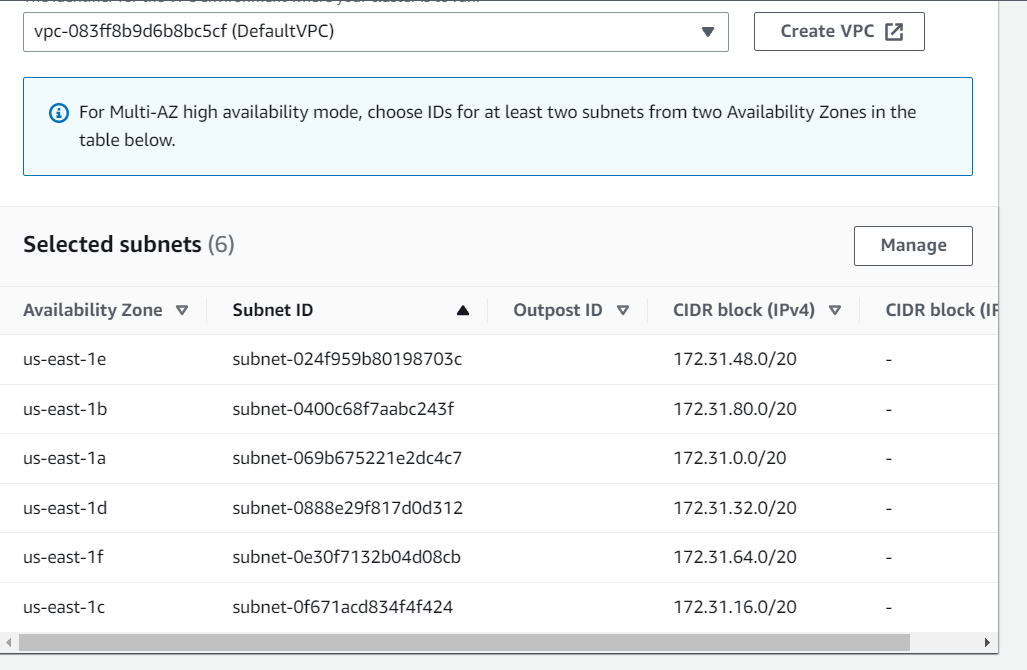
So we have created the Subnet Group named vprofile-elasticache-SubnetGroup as below with subnets of all the AZs exactly the same way we did for RDS:
Creating Parameter Group
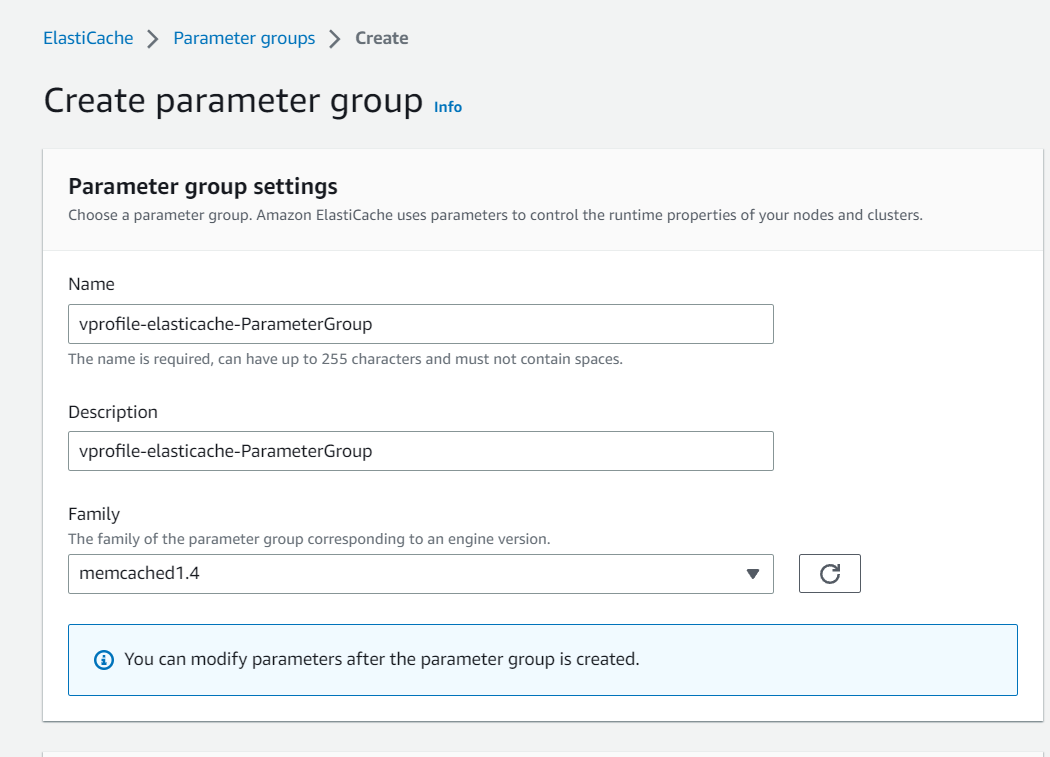
Here we have created a Parameter Group named vprofile-elasticache-ParameterGroup which has the same functionality as memcached1.4:
Creating Elastic Cache Cluster
In the Elastic Cache dashboard we have 2 options to choose from and as we have chosen Memcached in the Parameter Group we'll go with Memcached Cluster:
Step-1
Here we have specified the cluster name as vprofile-elasticache-svc , attached to the respective Parameter Group that we created earlier and Node Type is t2.micro which is the instance type that will be used for Elastic Cache:
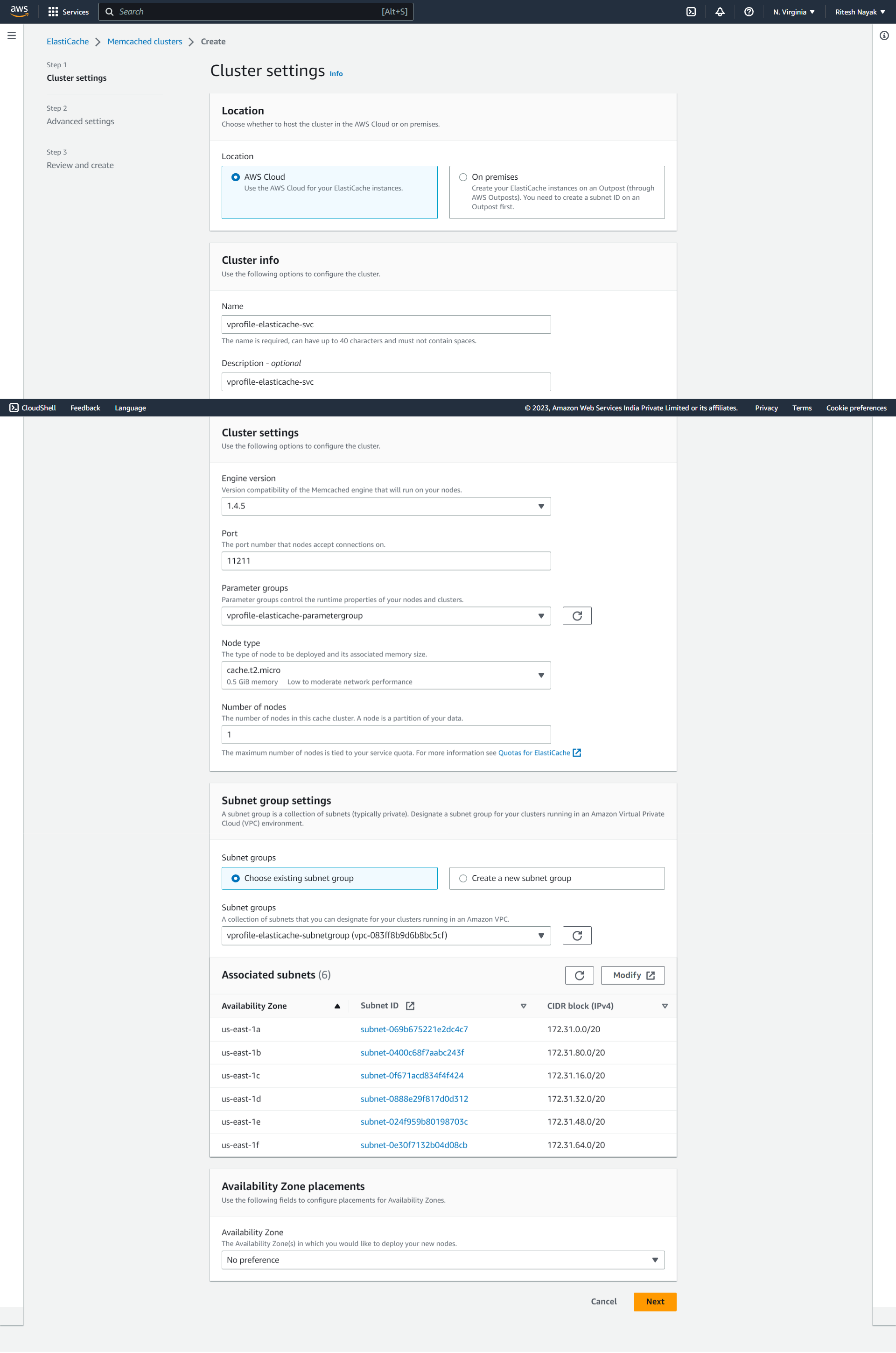
Step-2
Here we are attaching the elastic cache to the security group VProfile-backend-SG that we prepared earlier and also setting up the cloud watch alarm:
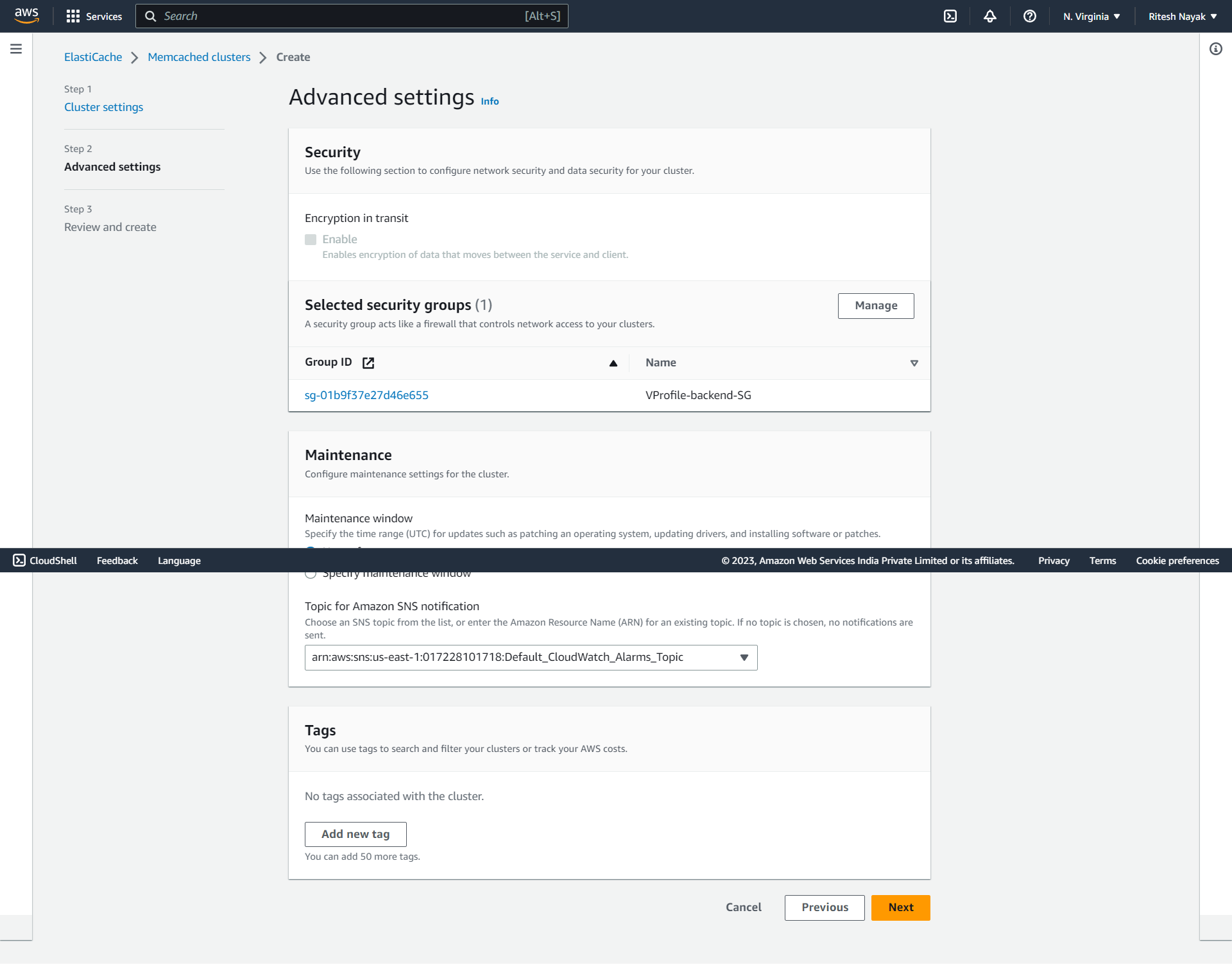
And with this, we have created our AWS-managed caching service for our application.
Step-5(Setting up Amazon MQ)

Now we'll be creating the AWS-managed broker service with will be a replacement for the RabbitMQ that we previously used as one of our backend services.
However, Amazon MQ will internally use the Rabbit MQ engine as per our requirement.
First of all, we are selecting the Broker engine type which is RabbitMQ for our project.
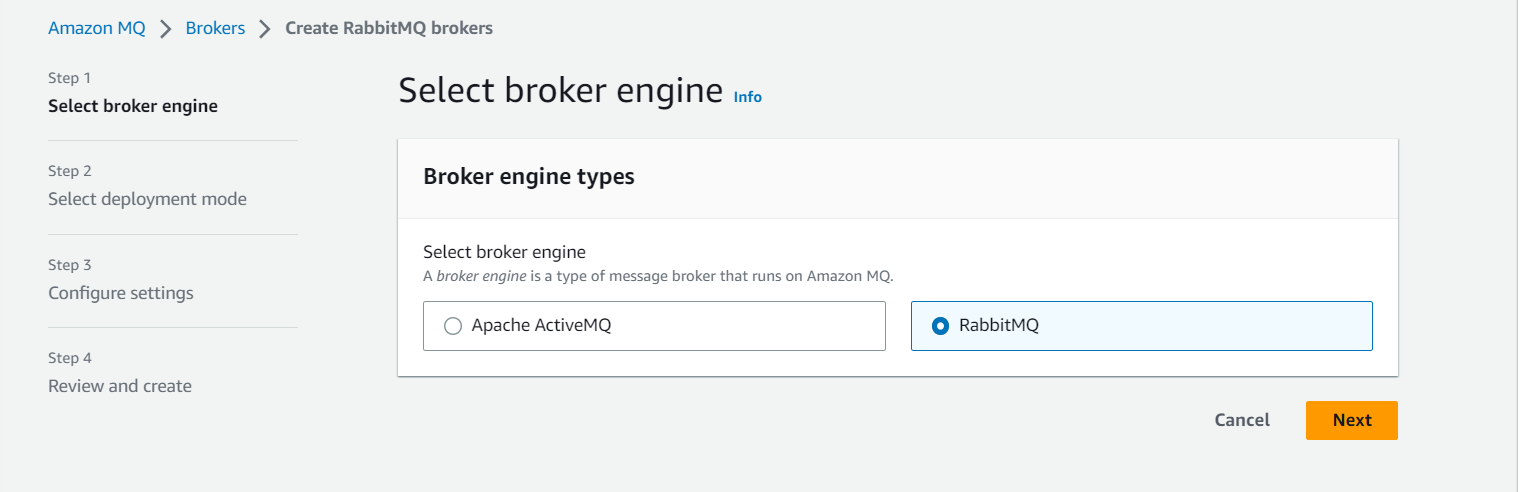
For our project, the deployment mode will be a Single-instance broker as we are deploying on a small scale. For large-scale production-level deployments, we should use Cluster Deployment:
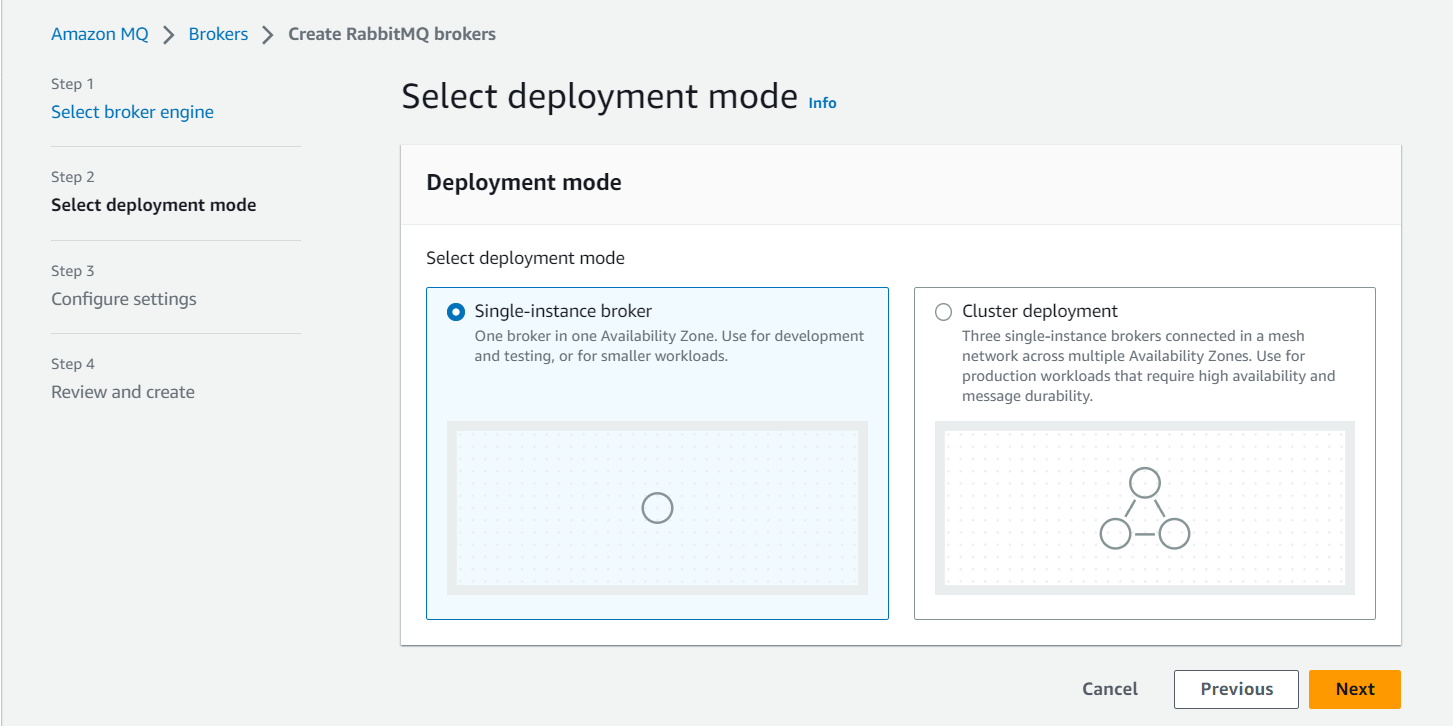
And for the configuration we have given the name as vprofile-rmq , attached it to the backend security group and the access type is private as it will be privately accessed by Beanstalk.
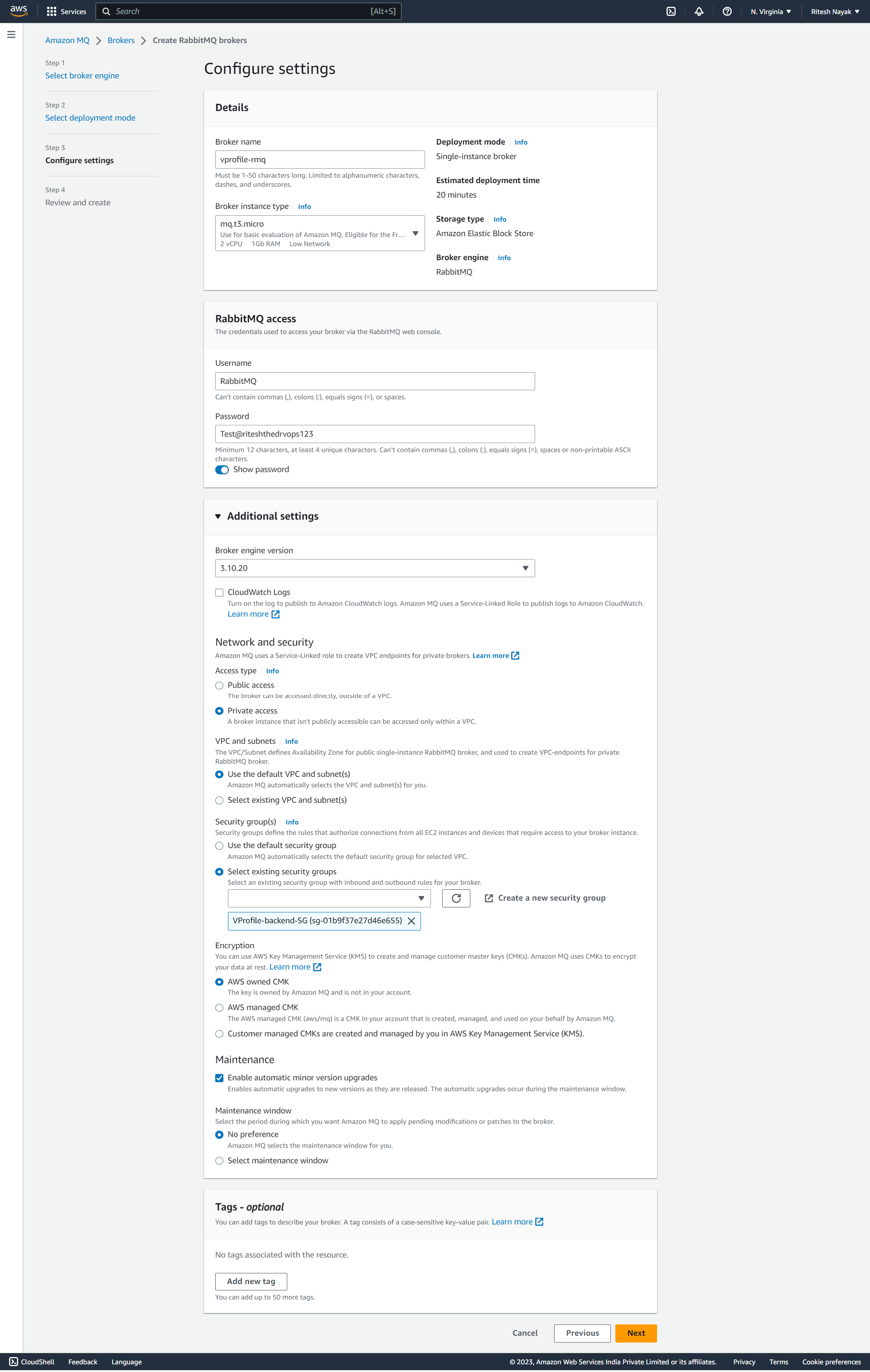
Step-6(DB Initialization)
We have set up all our backend services and now we just need to initialize the DB which will be the last step for our Backend Setup.
As we know, RDS is a PaaS service by AWS. It has provided the platform and required element to construct our DB however, it's our responsibility to make it workable according to our project requirement for which we have to initialize it by ourselves. To do so, we'll launch an EC2 instance and install the MySQL client( sudo apt install mysql-client ) that will help us to connect to the RDS endpoint.
logging in to RDS
mysql -h vprofile-mysql-db.cezpawefwtx5.us-east-1.rds.amazonaws.com -u admin -p
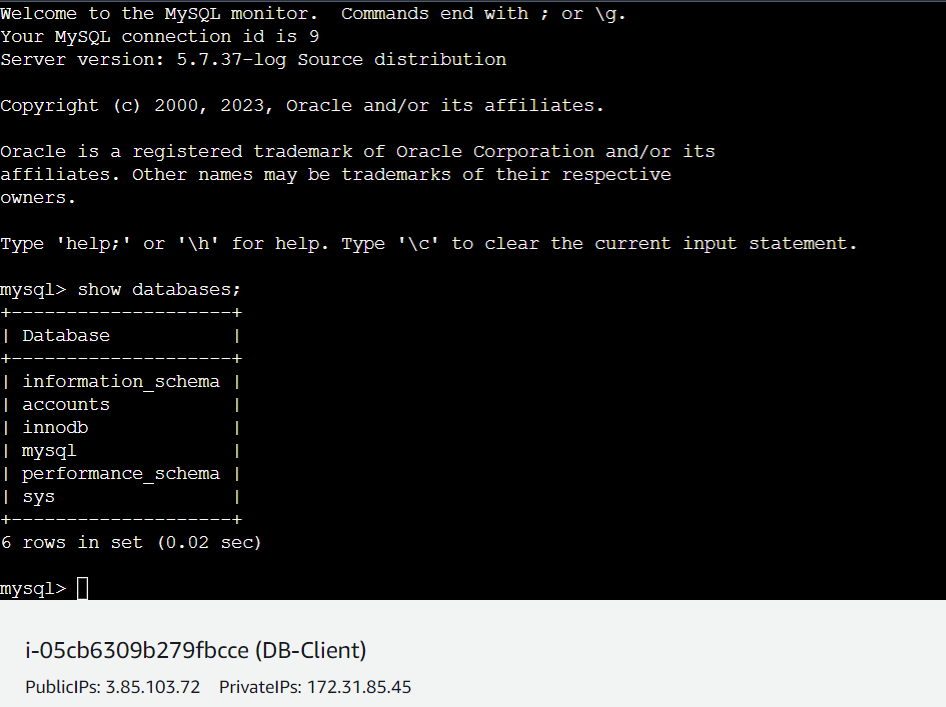
And above we can see that we have a database named accounts that we configured during RDS configuration.
Initialization
Now to initialize the account database we have to apply the schema that is there with our project and to do so we have to clone the project to our DB-Client instance.
git clone https://github.com/rkn1999/vprofile-project.git and move to the branch where our DB schema is available db_backup.sql
We have to initialize the DB with the above schema db_backup.sql with the same command mysql -h vprofile-mysql-db.cezpawefwtx5.us-east-1.rds.amazonaws.com -u admin -p accounts > db_backup.sql within the same directory where this schema is present.
And we got 3 tables created in our database accounts:
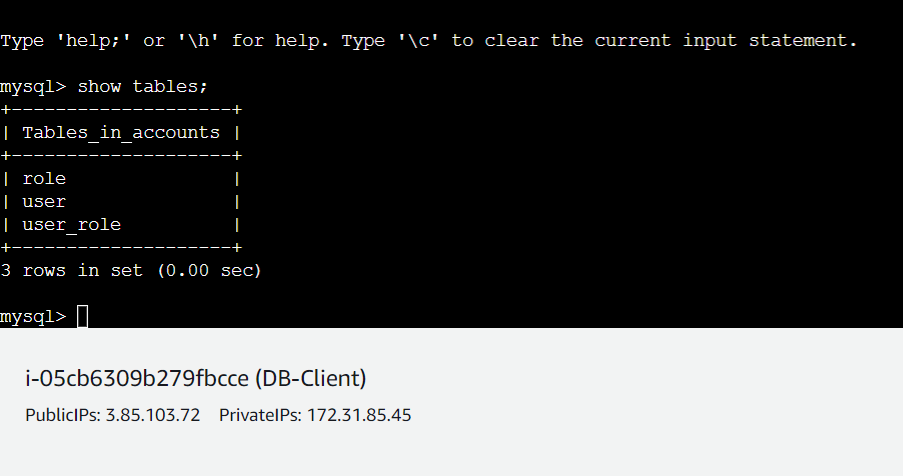
And with this, our DB initialization has been completed.
Step-7(Setting up Elastic Beanstalk)

Creating IAM Roles for Beanstalk
Beanstalk will launch several instances on our behalf so, we have to create an IAM Role as we usually do for EC2 instances and other services. Beanstalk also creates some roles by itself. To create roles move to IAM and create a role with the below permissions:
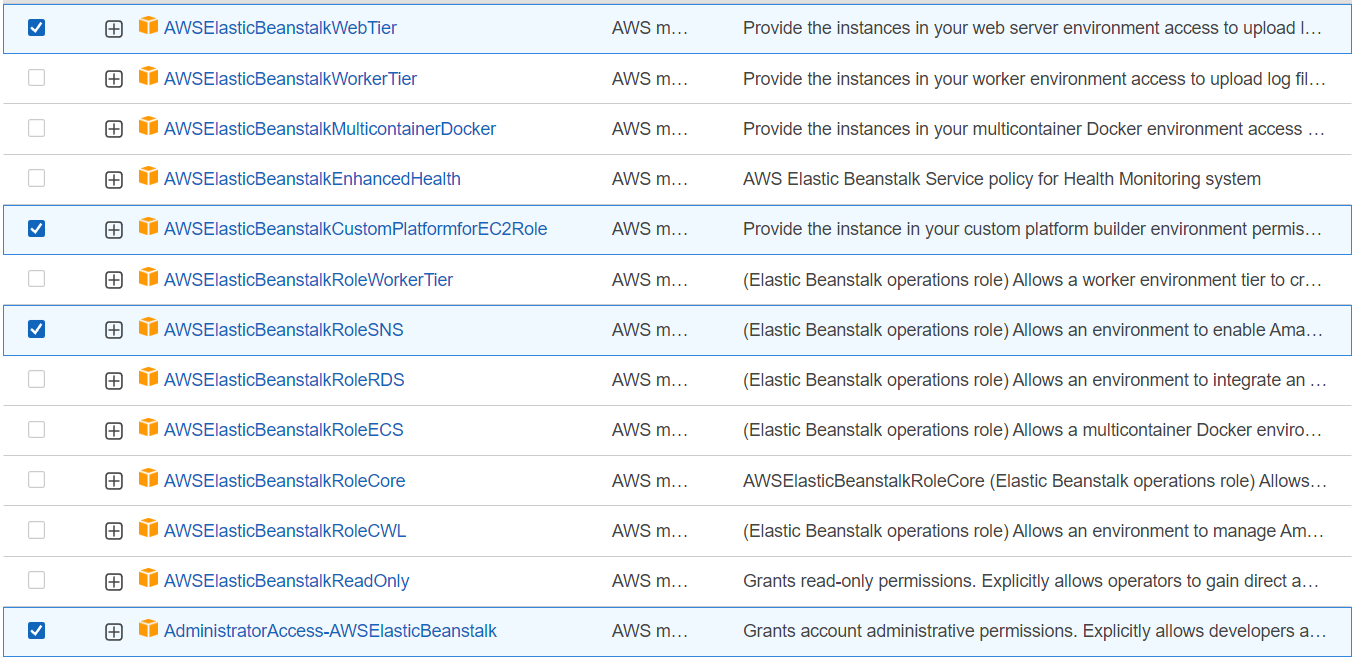
And the role is created:

Creating the Elastic Beanstalk
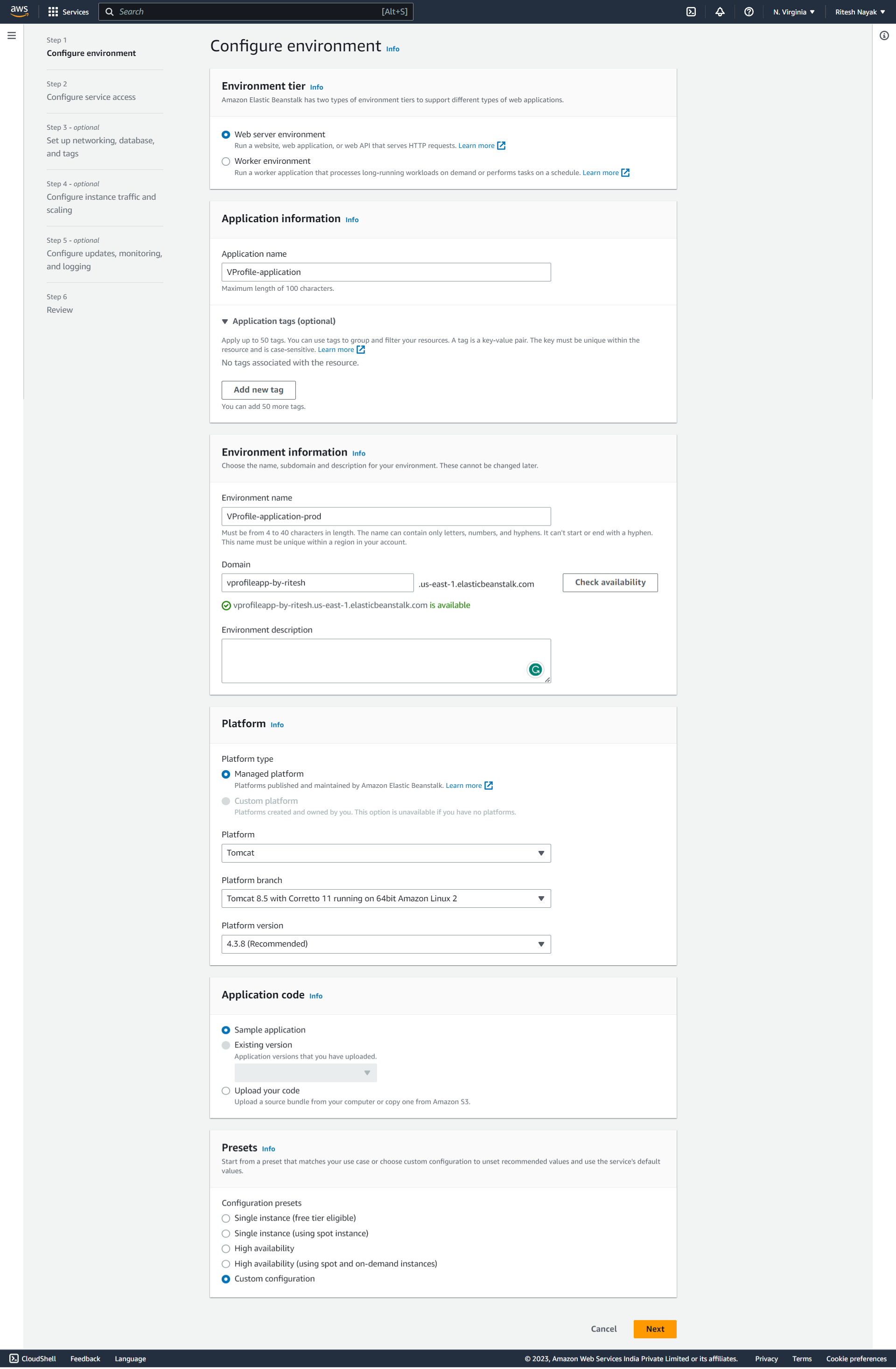
So, after creating the Roles we'll configure the Beanstalk for our application and the configuration would be as below:
- Our application is a webpage so for environment we are selecting Web Server, name has been given to our project and the domain name is
vprofileapp-by-ritesh.us-east-1.elasticbeanstalk.comthat has to be unique. Platform is chosen as Tomcat as our application artifact will be deployed to Tomcat server so beanstalk will take care of that.
Below we have given respective role configuration as well as the key-pair for the EC2 instances that will be created by Beanstalk.
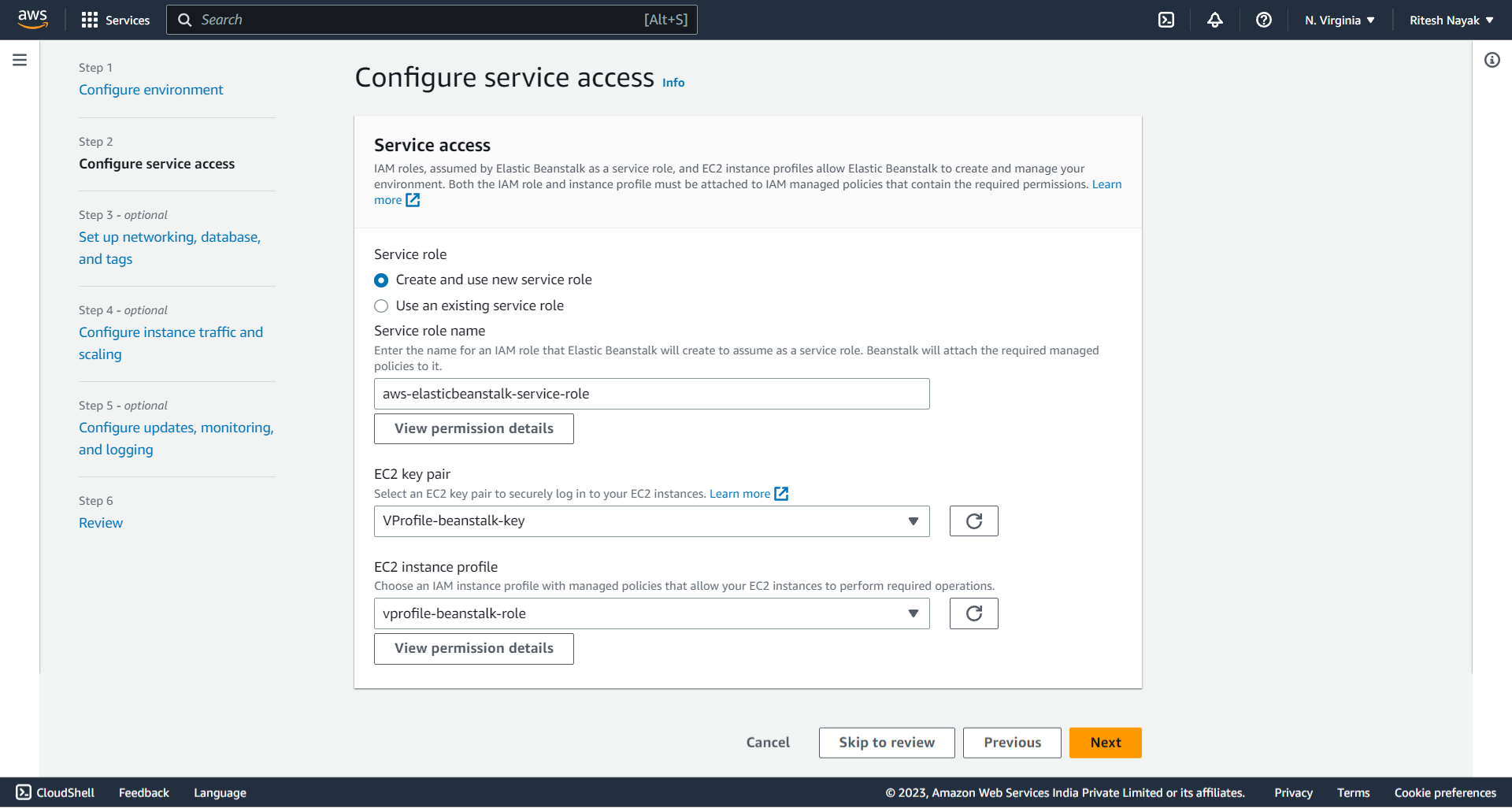
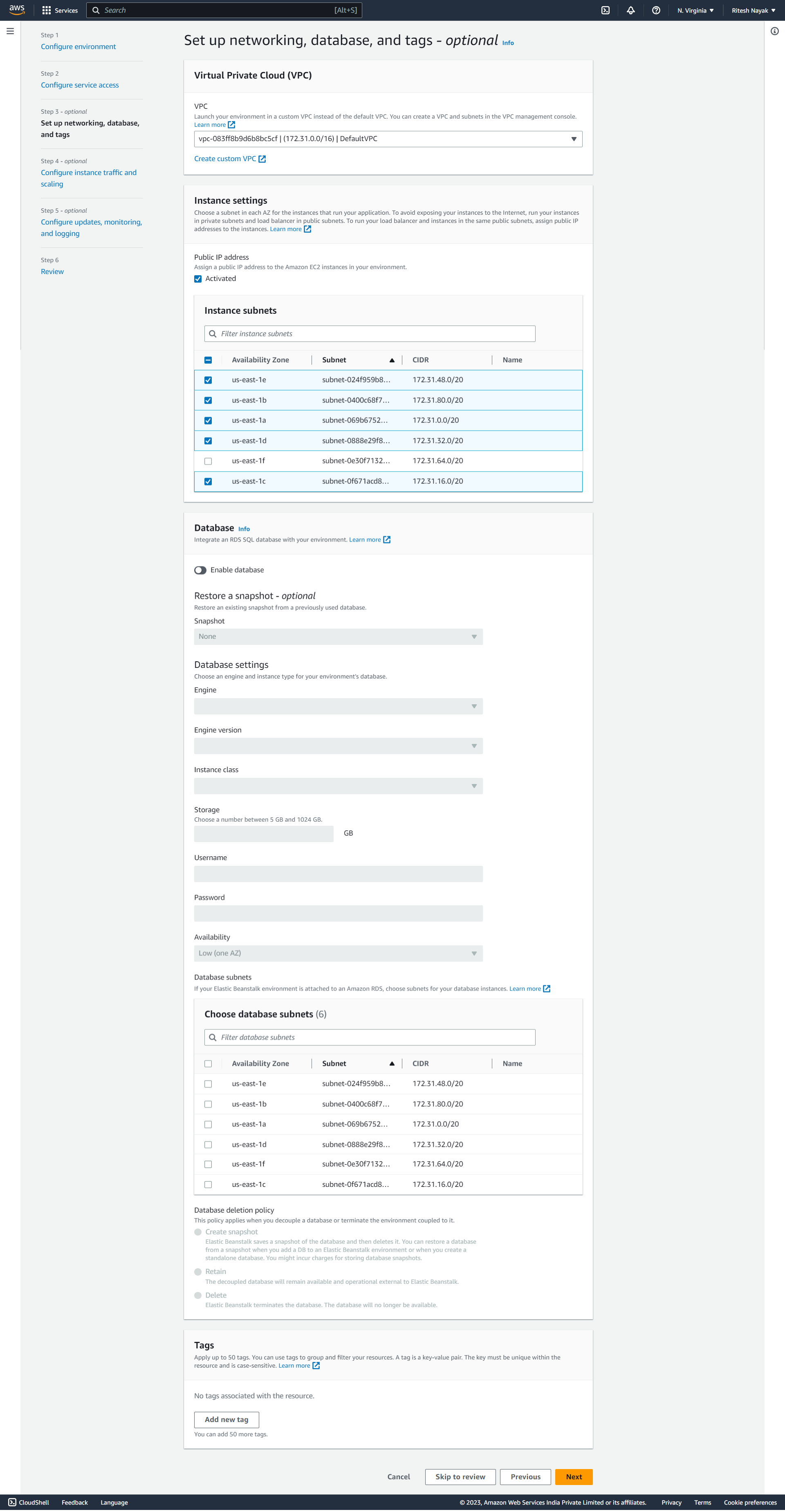
At this step, VPC is set to default,we have chosen multiple subnets so that it can launch instances on different subnets and high availability. For Databases we are using RDS explicitly hence, here we have left this blank, this database will be created by Beanstalk and it will also be deleted along with the instance deletion so, it is not recommended for production usage, it's good for Dev and Test environments.
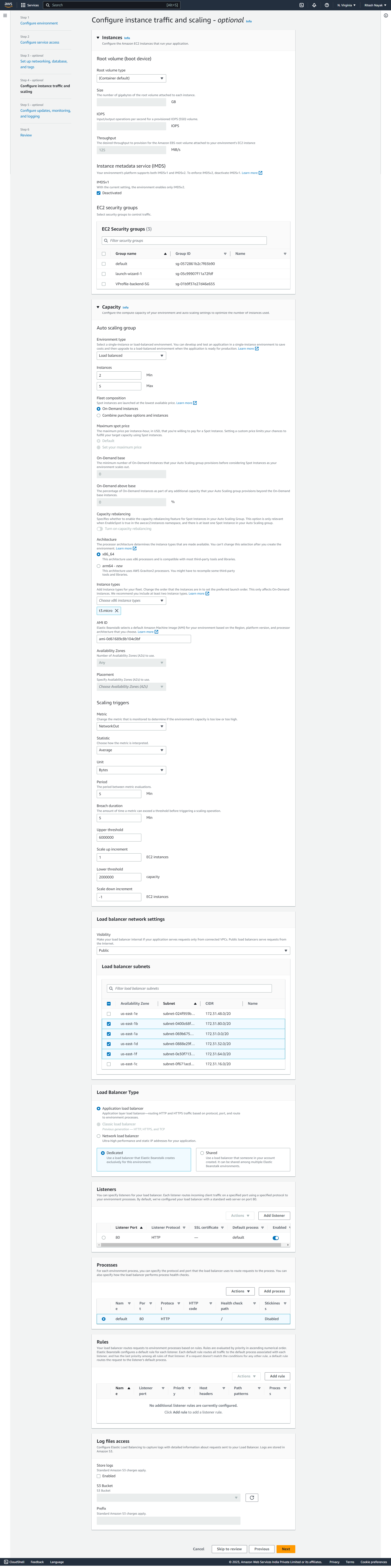
At this step we have configured volume, load balancing and autoscaling based on the network traffir.
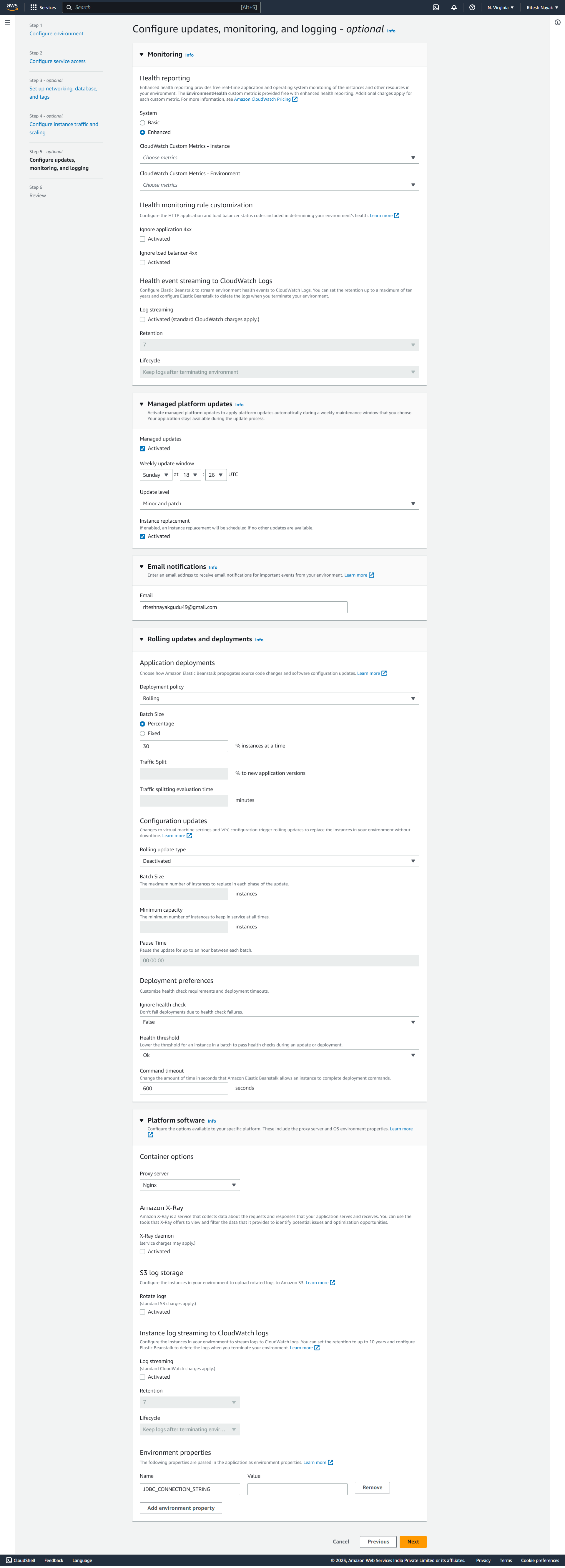
At this step we have configured update and monitoring. the rolling update section is very much important that works on basis of the deployment policies.
And finally, our stack is complete as we have submited the stack which is getting created as below, once it is done we can be able to access .
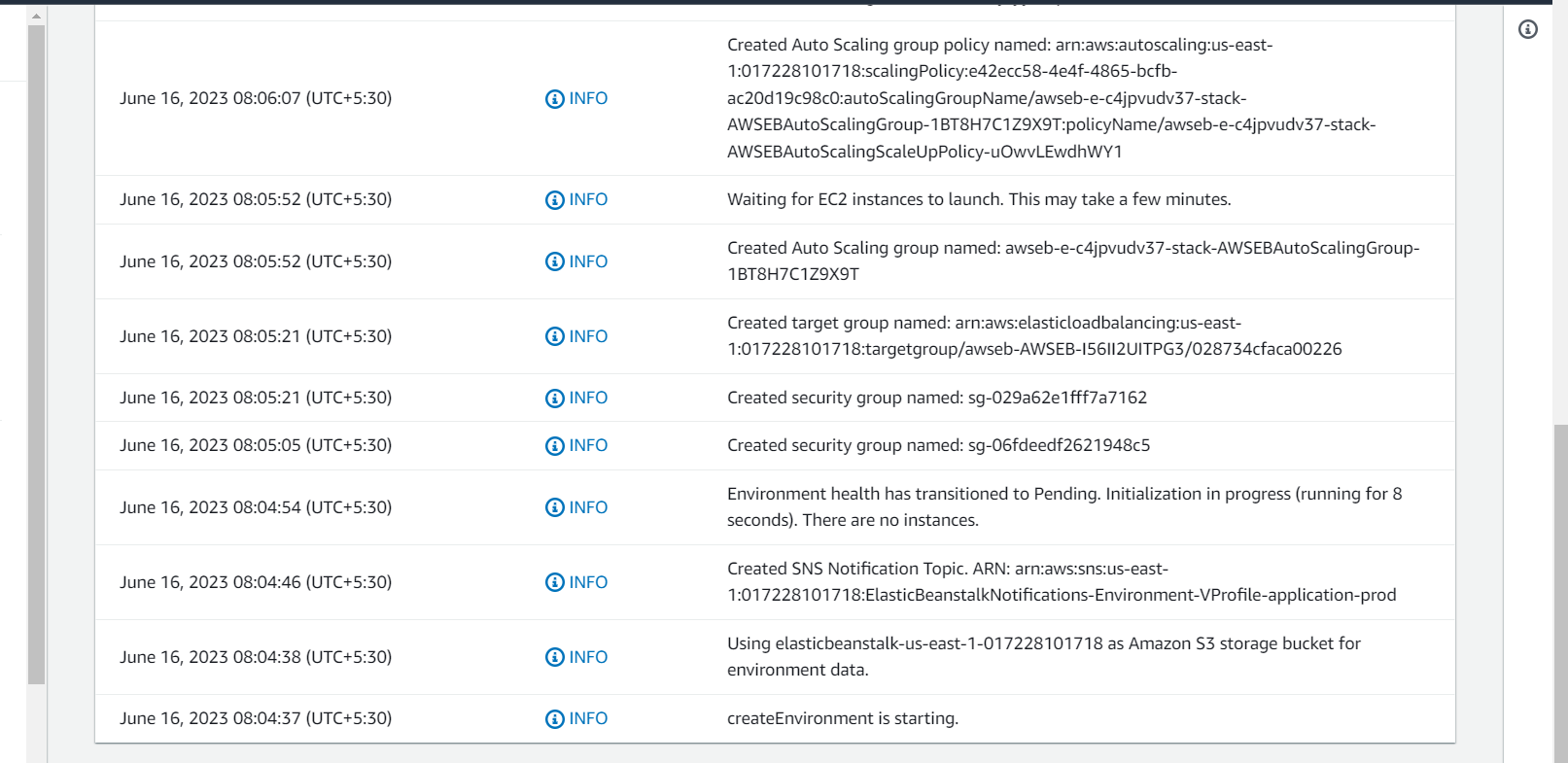
With the configuration our stack is completed and it has deployed a dummy application as below that will be replaced by our application:
Step-8(Updating Security Group & ELB)
Here we'll do 3 things:
1) Enable ACL in S3 Bucket
2) Update the health check in the Target Group
3) Update Security Group
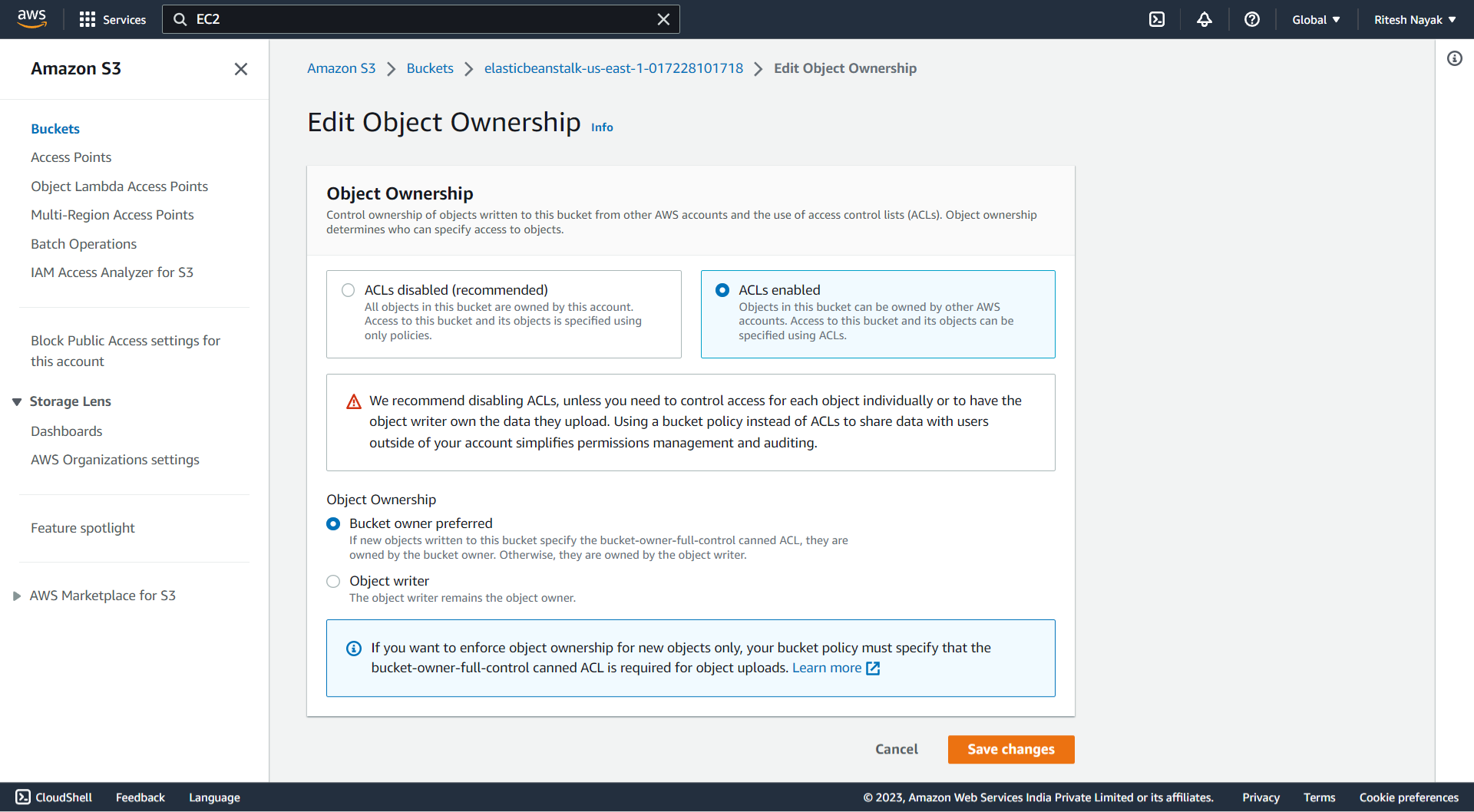
Enable ACL in S3 Bucket
ACL stands for Access Control List, It is a mechanism that allows you to control access to your S3 buckets and objects within them. ACLs are used to specify who can perform specific actions (such as read, write, or delete) on your S3 resources. With ACLs, you can grant permissions to individual AWS accounts or predefined groups (such as Amazon S3 Log Delivery group) to control access at the bucket or object level.
Here we'll be enabling the ACL for Elastic Bean Stalk so that it can access the artifact that will be uploaded to S3 bucket without any error at S3-bucket level. To do so we have to Enable the ACL with the below configuration which means only the bucket owner can have the access so that, it can while beanstalk resources of my account will try to access the objects in this elasticbeanstalk-us-east-1-017228101718 bucket, it will allow the request:
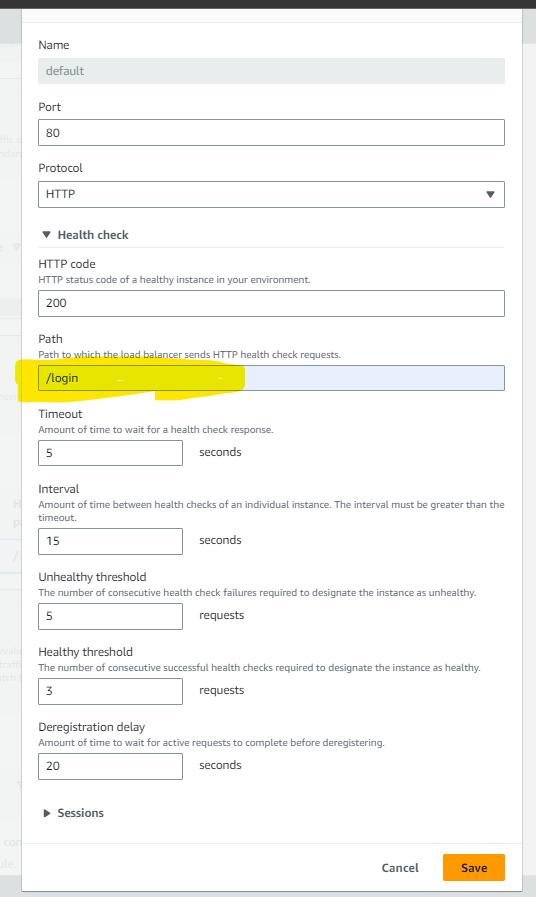
Update the Health Check Path in the Target Group
Our application Vprofile listens at the URL "/login"and the Target Group will perform the Health Check on this path. So that, we have to change the in the health check path as below and to do so: move to the Elastic Beanstalk > Environments >VProfile-application-prod > Configuration > Instance traffic and scaling > Processes :
Adding Listener:
Here we are adding HTTPS listener at the port 443 to access the application on this on this port:
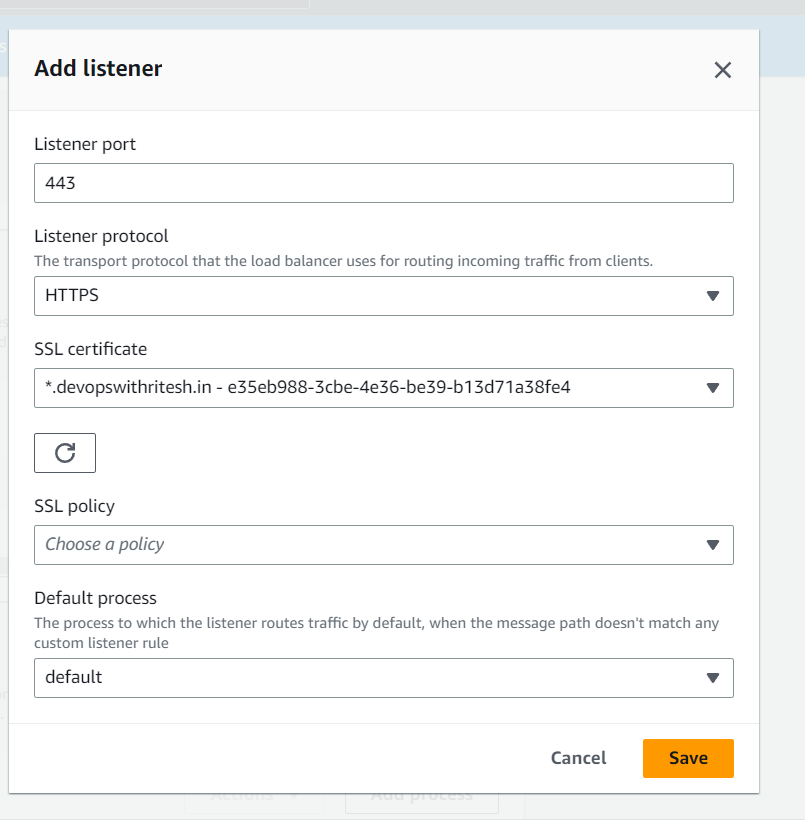
Update Security Group
We have update the security group because all our backend services such as RDS, Amazon MQ, and Elastic Cache are in backend security group. Instances of the Beanstalk will access these backend services at their respective port numbers so that
Here we have to take the Security Group ID of the instances that are up by Elastic Beanstalk for our application deployment and have to tie it up with Backend Security group so that it will have access through this:
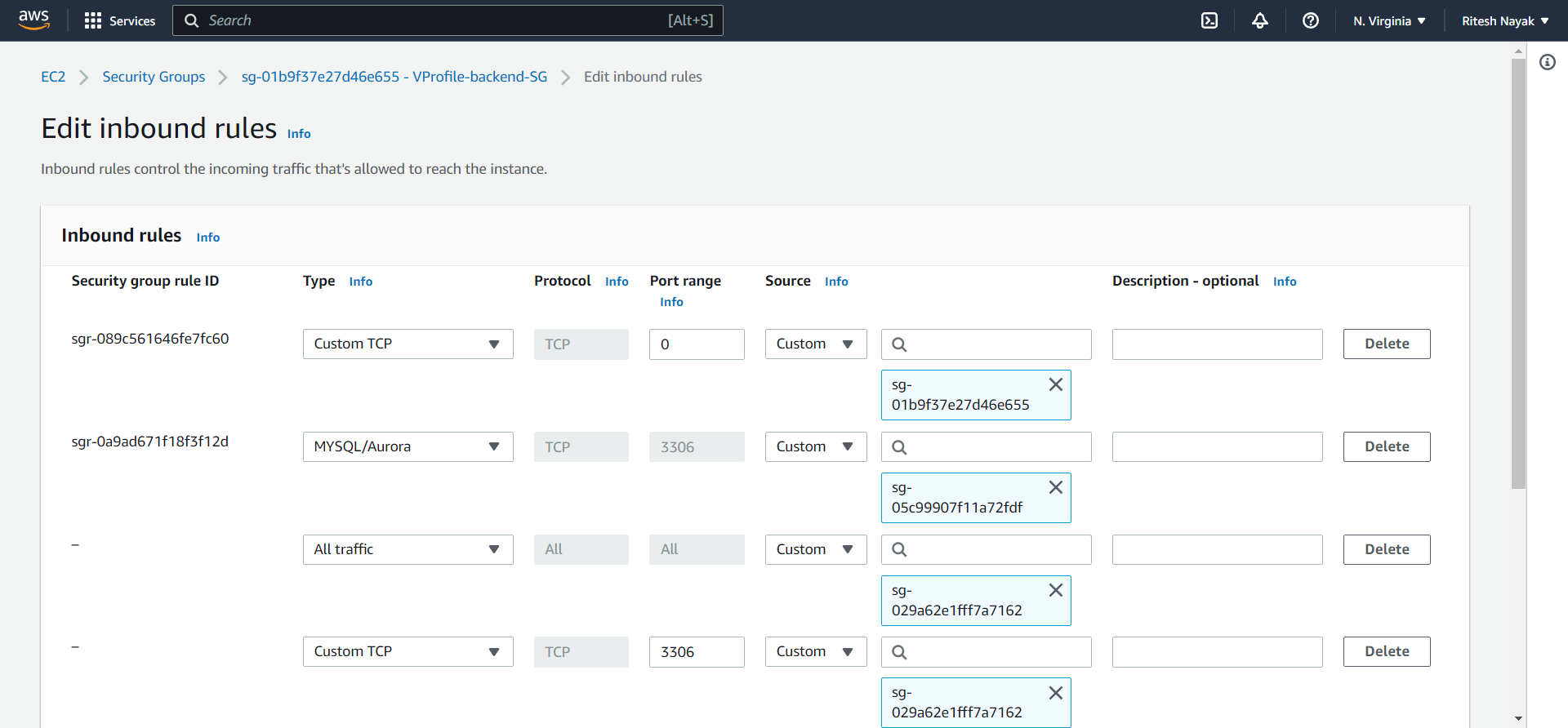
Now the backend security group is allowing the traffic from the front-end security group(Instance Security Group).
Step-9(Project Build & Upload Artifacts)
At this step we'll build our application source code with maven that will generate the deployable artifacts which will further be uploaded to S3 bucket.
Before building the source code we have to update the application.properities file in the project with all our backend server information which is like the below where we have added the endpoints of the services and saved it.
#JDBC Configutation for Database Connection
jdbc.driverClassName=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://vprofile-mysql-db.cezpawefwtx5.us-east-1.rds.amazonaws.com:3306/accounts?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
jdbc.username=admin
jdbc.password=LinkDYymco62ZWFy7rRG
#Memcached Configuration For Active and StandBy Host
#For Active Host
memcached.active.host=vprofile-elasticache-svc.plafv0.0001.use1.cache.amazonaws.com
memcached.active.port=11211
#For StandBy Host
memcached.standBy.host=127.0.0.2
memcached.standBy.port=11211
#RabbitMq Configuration
rabbitmq.address=b-8e65c9d5-6d03-4828-bcb5-75c427966934.mq.us-east-1.amazonaws.com
rabbitmq.port=5671
rabbitmq.username=RabbitMQ
rabbitmq.password=Test@riteshthedrvops123
#Elasticesearch Configuration
elasticsearch.host =192.168.1.85
elasticsearch.port =9300
elasticsearch.cluster=vprofile
elasticsearch.node=vprofilenode
Build( mvn install )
With mvn install we have built the project and generated the war file.
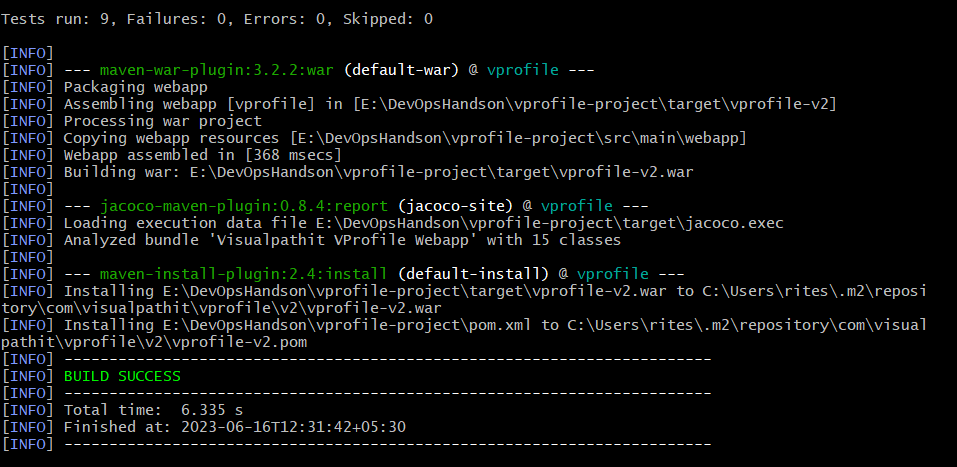
And we have got the .war file in target folder which we'll be uploading to S3:

Step-10(Upload & Deploy)
With this we are uploading the artifact from the beanstalk environment :
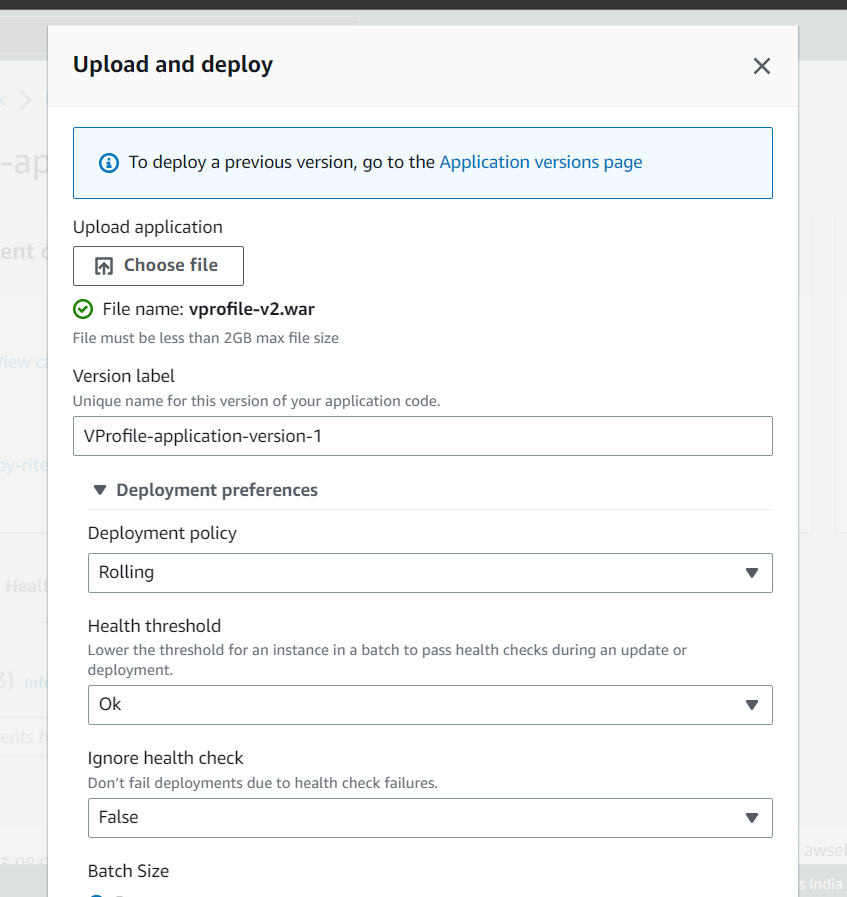
And here you can see the artifact is listen in Application version and we need to upload it:
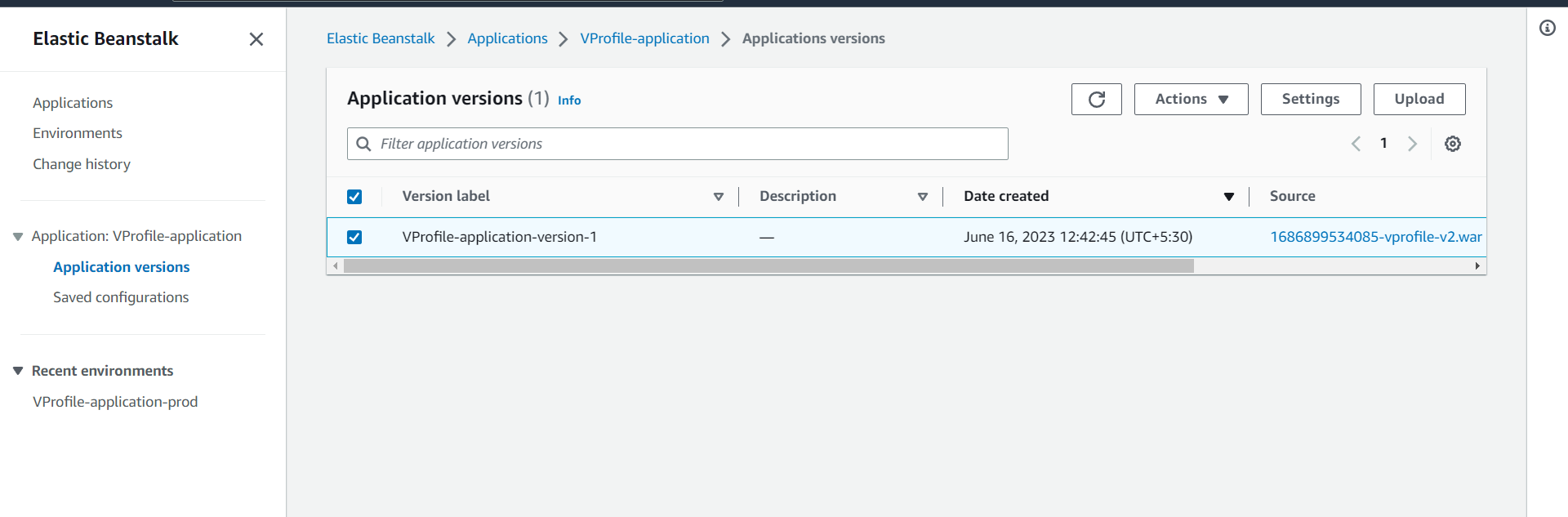
And then from the actions drop down we can deploy it to the environment we want. Here we have only on environment that is Prod so we are deploying to that environment:
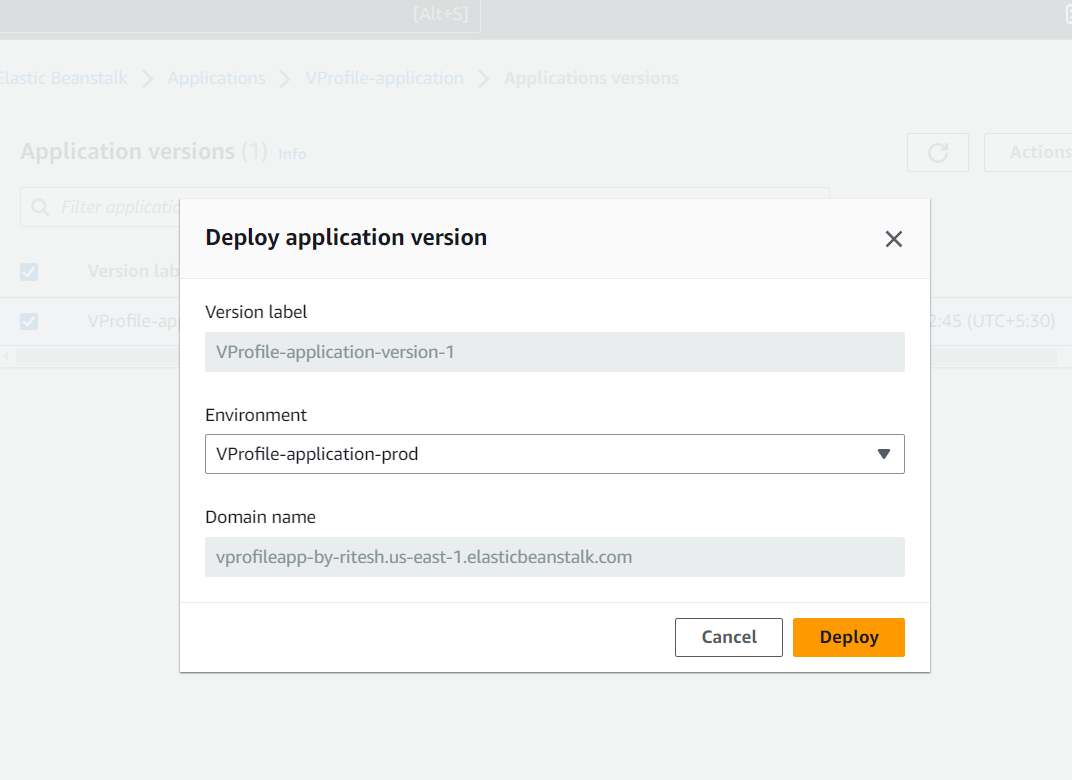
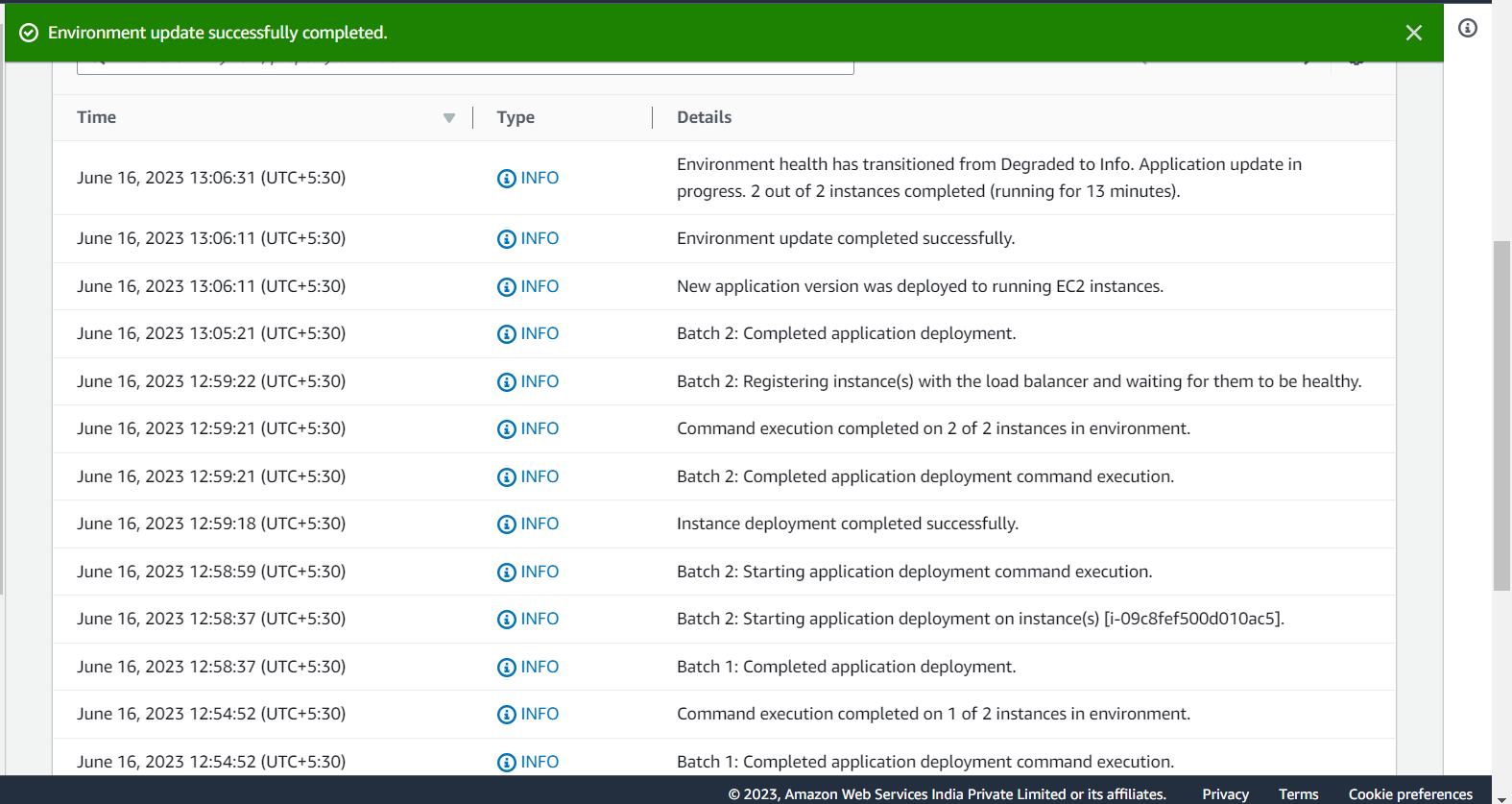
And finally the deployment has been completed to the beanstalk:
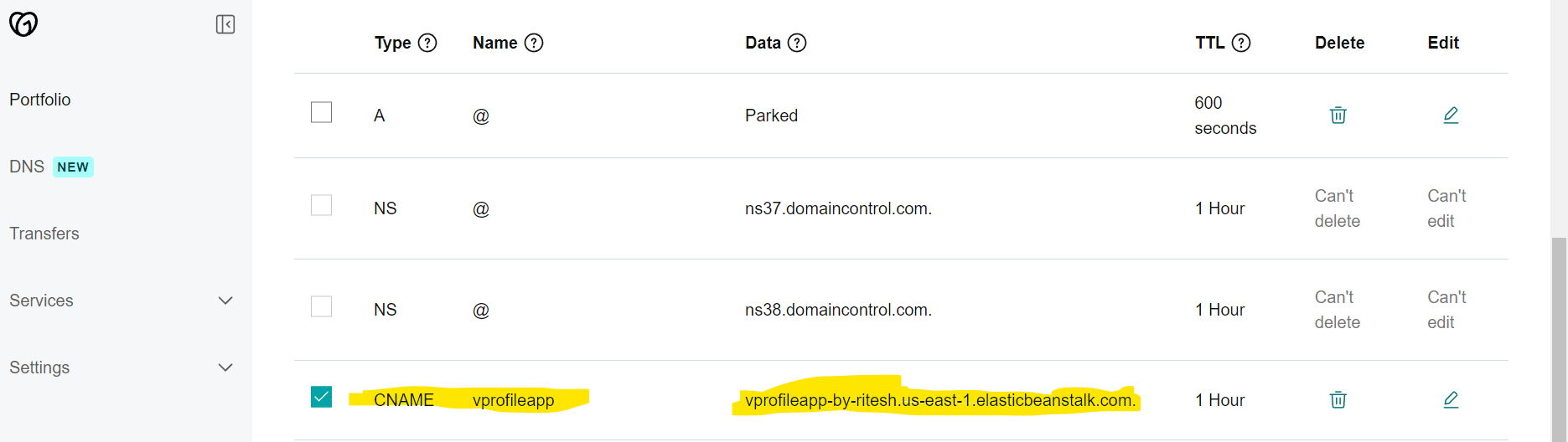
Step-11(Updating CNAME record in GoDaddy DNS)
Now, the domain of the Beanstack Environment vprofileapp-by-ritesh.us-east-1.elasticbeanstalk.com will be added to the CNAME record in GoDaddy DNA as below:
Finally the app is up :
CloudFront( Content Delivery Network by AWS)
AWS Cloud Front is a content delivery network by AWS that helps us to serve our application across multiple Regions.
Currently our application is hosted in N. Viriginia region and with the use of CloudFront service this application can be deployed across multiple Regions.