Kubernetes(K8S) E2E Project-2

Passionate about helping organizations build scalable infrastructure and DevOps solutions with cloud technologies. Experienced in designing robust systems, automating processes, and driving efficiency through innovative cloud solutions. Advocate for best practices in DevOps and cloud computing, committed to enabling teams to achieve their full potential.
What is Deployment?
A Deployment is a higher-level object in the Kubernetes object model that manages the creation and updates of Pods. A Deployment ensures that a specified number of replicas of a Pod are running at any given time, and automatically replaces failed or terminated Pods. It provides a declarative way to manage Pods, allowing you to define the desired state of your application and let Kubernetes handle the process of getting the actual state to match that desired state.
In summary, Pods are the building blocks for running applications in Kubernetes, while Deployments are responsible for managing and maintaining the desired state of those applications.
How does this architecture work?

Deployment over Pod
Previously we understood that in a single Node, there can be multiple Pods and each pod is nothing but a docker container. Pods can be used in production, but they are often used in combination with higher-level objects such as Deployments or StatefulSets. This is because, while Pods provide a simple way to run containers, they lack many of the features required for production-grade deployment and management of applications, such as self-healing, rolling updates, and scaling.
For example, if a Pod fails, it will not be automatically recreated, and you will have to manually create a new Pod to replace it. Similarly, if you need to update your application, you will have to manually update each Pod, which can be time-consuming and error-prone.
By using higher-level objects such as Deployments, you can take advantage of features such as automatic rolling updates and self-healing, which can greatly simplify the process of deploying and managing applications in production. Additionally, these objects provide a higher level of abstraction, making it easier to manage and reason about your application as a whole, rather than individual Pods.
In conclusion, while Pods can be used in production, they are typically used in combination with higher-level objects, such as Deployments, to provide a more robust and scalable production environment.
Pod.yaml vs Deployment.yaml
A Deployment YAML file specifies the desired state of the Deployment and here against the field "kind" it will be "deployment", including the number of replicas to run and the template for the Pods. The Deployment will create and manage Pods that match the template and ensure that the desired number of replicas are always running and maintained, even if some Pods fail or are deleted.
In comparison, a Pod YAML file specifies the desired state of a single Pod, including the containers it should run and the resources it should use. A Pod YAML file is useful for testing and development, but for production deployments, it's recommended to use a Deployment, which provides more robust and scalable management of your Pods. Pods do not have auto-healing, or autoscaling capabilities as well which is the measure drawback of pods when it comes to large-scale production deployments.
In summary, the Deployment YAML file is used to manage a group of Pods, while the Pod YAML file is used to define a single Pod.
Hands-On Project Illustration
Note:
Before jumping into Handson make sure you have all the required setup done in your system.
However previously, we used pod.yaml for a single pod creation and now we will be using deployment.yaml as the configuration file for multiple pods and real-world Container Orchestration.
This one was the pod.yaml file for Pod creation :
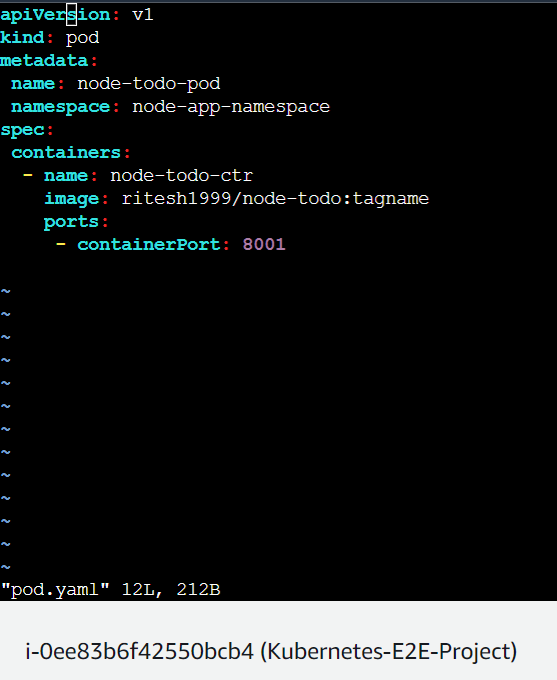
We'll understand the complete deployment.yaml file below.
Step-1(Creating a Deployment file)
apiVersion: Specifies the version of the Kubernetes API being used. In this case, it isapps/v1.kind: Specifies the type of resource that is being defined. In this case, it is a Deployment. When you define the kind as deployment, it brings additional features to deployment.yaml file over pod.yaml file such as creating replicas, auto-healing, auto-scaling etc.metadata: Contains information about the Deployment, such as its name (node-app-deployment) and labels (app: node-todo).name: it defines the name of the deployment or the name of the app. It helps to identify the deployment. You can give any readable and easy-to-identify name.labels: this keyword is used to define labels that are attached to the Deployment. Labels are key-value pairs that can be used to categorize and identify resources in Kubernetes, such as Pods, Services, and Deployments. For example, in the following YAML file, the Deployment is labeled withapp: node-todoyamlCopy codeapiVersion: apps/v1 kind: Deployment metadata: name: node-deployment labels: app: node-todo spec: ...These labels can then be used to select the Deployment and its associated Pods, for example:
kubectl get pods -l app=node-todoThis will return all Pods that are labeled with
app: node-todo.namespace: It defines the namespace under which the pods of this app will be categorized. In our case, it will be node-app-namespace as we have created this name for our project.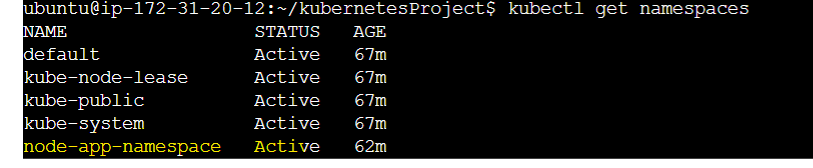
spec: Contains the specifications for the Deployment.replicas: Specifies the number of replicas of the app to be created. In this case, it is set to4.selector: Specifies the labels that the Deployment should match to determine which Pods it should manage. In this case, it matches pods with the labelapp: node-todo.matchLabels: this keyword comes under the selector keyword which matches the name of the label defined above hence it is named as matchLabels.
For example, the following YAML file specifies a selector with the key app and the value nginx:
yamlCopy codeapiVersion: apps/v1
kind: Deployment
metadata:
name: node-app-deployment
spec:
replicas: 3
selector:
matchLabels:
app: node-todo
template:
metadata:
labels:
app: node-todo
spec:
...
In this example, the Deployment will only manage Pods that have the label app: node-todo. If any Pods are created without this label, or if any existing Pods lose this label, the Deployment will update or replace them to ensure that the desired number of replicas are running and match the selector.
template: Specifies the Pod template that will be used to create the Pods managed by the Deployment.metadata: Contains information about the Pod, such as its labels (app: node-todo).spec: Contains the specifications for the Pod.containers: Specifies the containers that will run in the Pod.name: Specifies the name of the container. In this case, it isnginx.image: Specifies the Docker image that the container should run.ports: Specifies the ports that should be exposed by the container. In this case, it is8001.
Step-1.2(Final deployment file)
NB: Make sure the indentations and keyword spellings are correct else errors will be thrown.
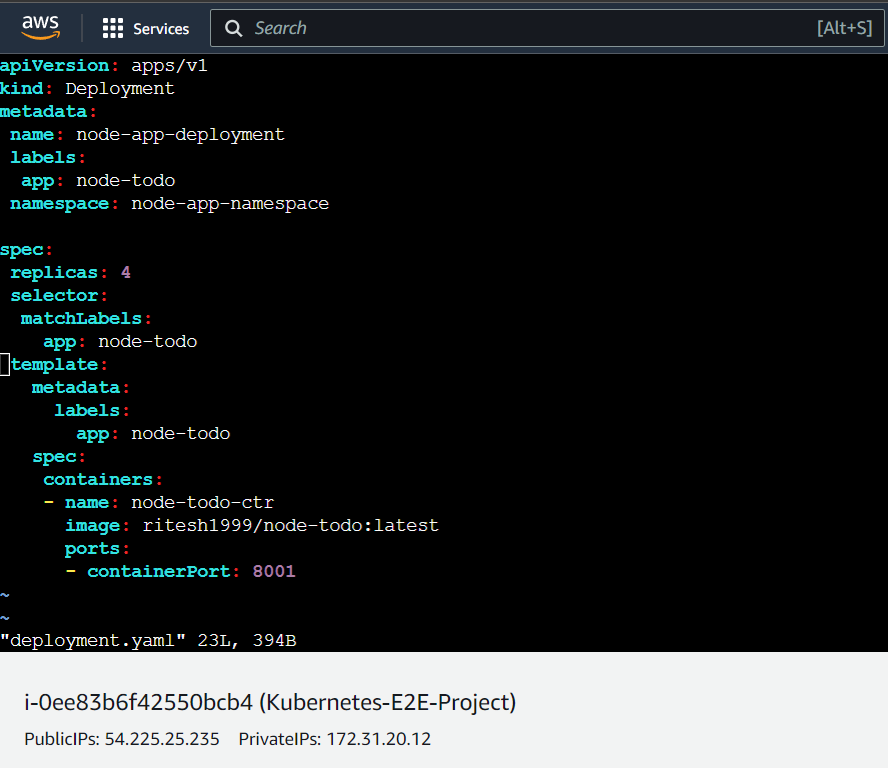
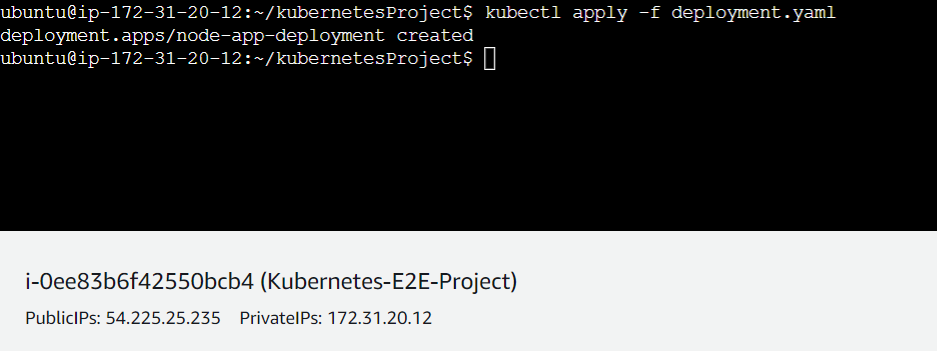
Step-2(Running the deployment.yaml)
$ kubectl apply -f deployment.yaml this command will execute the deployment file and run the required pods distributedly.
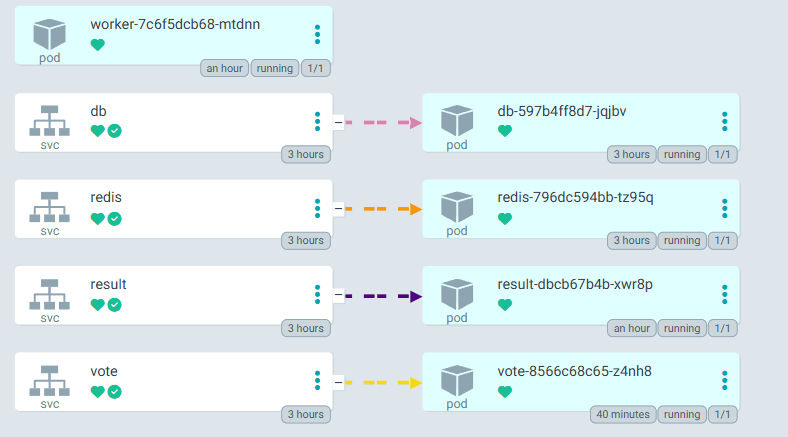
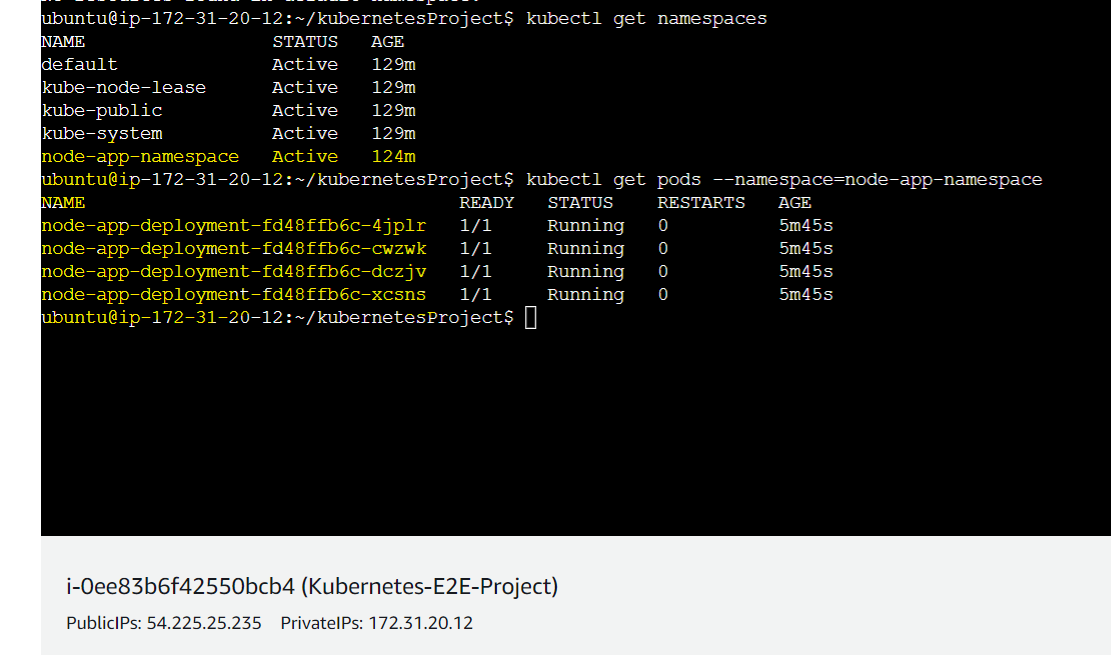
Step-2.1(Verifying the pods are up and running)
In the below picture, we can see using the command $ kubectl get pods --namespace=node-app-namespace that 4 pods are running under the namespace node-app-namespace because in the deployment.yaml file we have defined replicas: 3 .
Step-3(Auto Healing on termination)
Here we will delete a particular pod intentionally with the command kubectl delete pod --namespace node-app-namespace node-app-deployment-fd48ffb6c-4jplr where node-app-deployment-fd48ffb6c-4jplr is pod name which will be deleted and another pod will be up and running automatically.
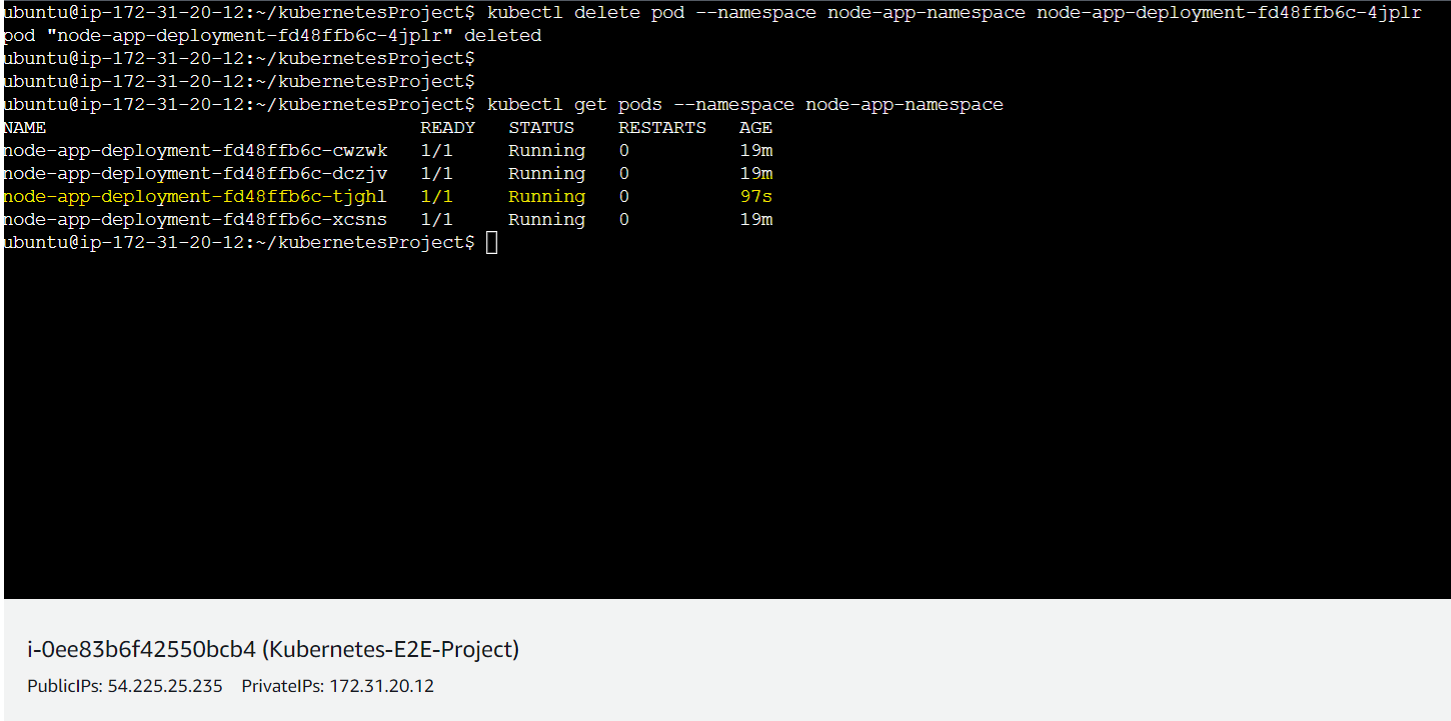
So now from the above picture, a new pod named as node-app-deployment-fd48ffb6c-tjghl has been auto-generated.
Step-4(Re-configuring the deployment.yaml)
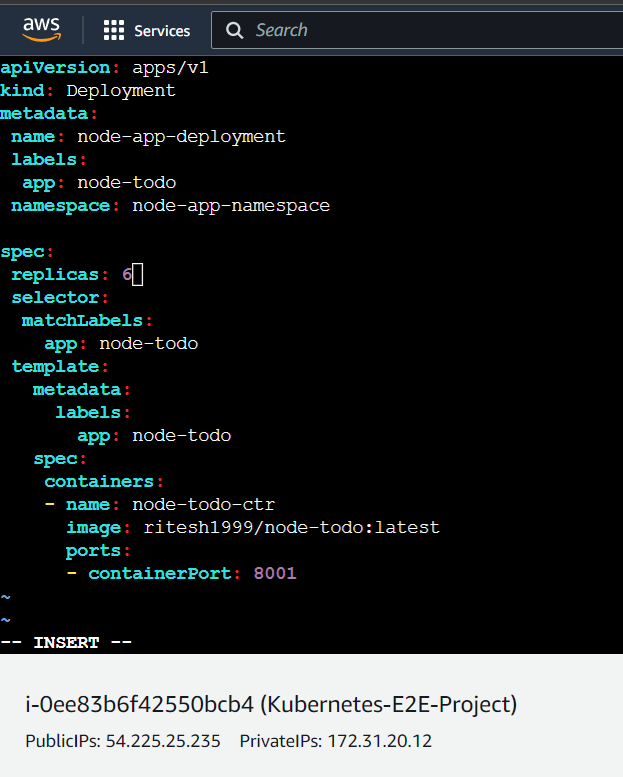
Suppose, due to more traffic have to increase the number of pods running. In that case, we just need to increase the number of replicas and again apply the changes with the command $ kubectl apply -f deployment.yaml .
Here we have increased the replicas from 4 to 6:
And now after applying we will see a success message below in which says node-app-deployment configured :
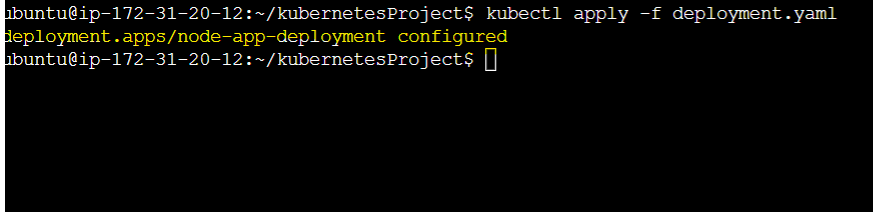
Now we can see 2 more replicas have been created recently:
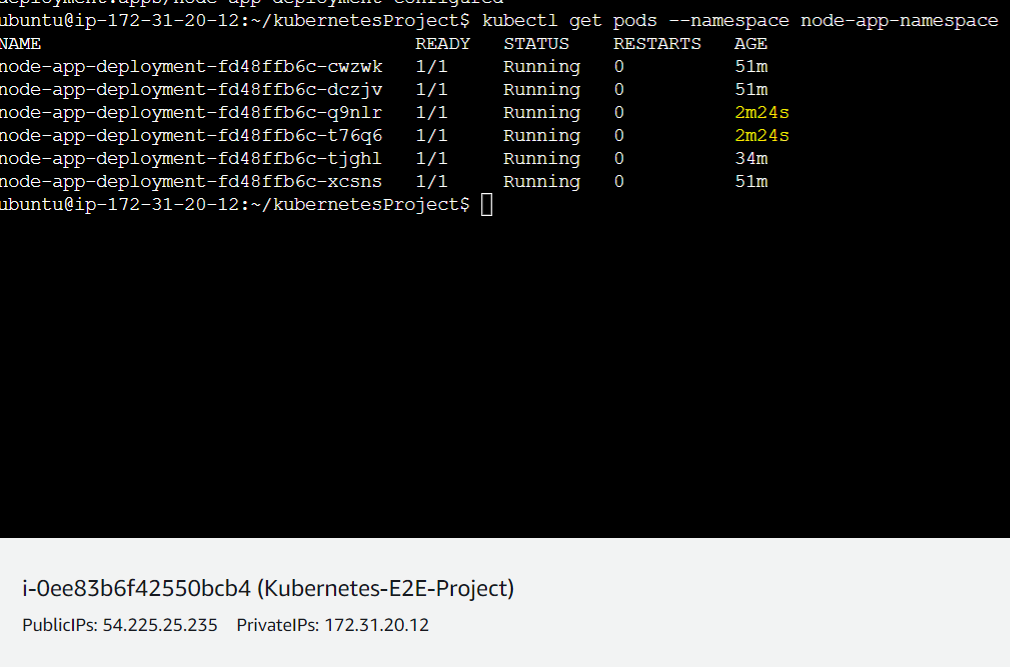
Similarly, we can down-scale the pods just by decreasing the number of replicas and configuring it again.
Step-4.1(IP addresses of the Pods)
$ kubectl get pods --namespace node-app-namespace -o wide : this command will give details of the pods along with their IP addresses. Here, all the IPs are different and it will keep changing every time a new replica is created due to any reason whether it's termination or failure.
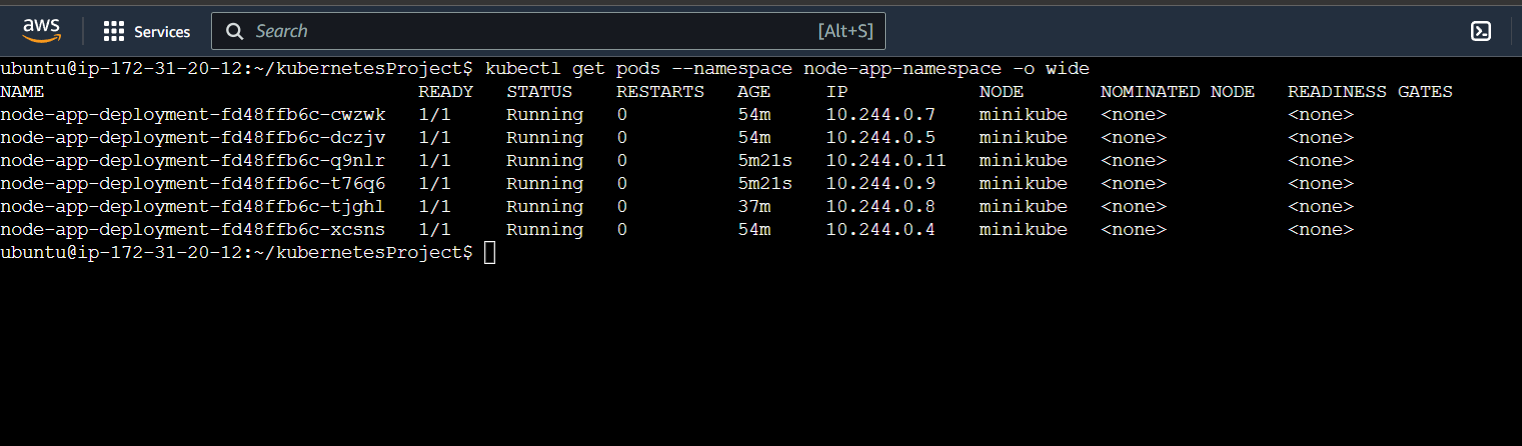
Drawback
Until now our application is running inside the pods only, these are not available to be accessed outside or from the browser. To overcome this Kubernetes has some services which will redirect these multiple IPs of pods to a single IP which we can then expose outside. Services are of 4 types( NodePort, ExternalName, LoadBalancer) and we can configure them in a YAML file, unlike Deployment.yaml file. In this project, we are using NodePort.
Node Port
A NodePort is a type of Kubernetes Service that exposes a Service on a static port on each node in the cluster, in addition to the cluster-internal IP address. The NodePort provides a way to access the Service from outside the cluster, using the IP address of any node in the cluster and the specified NodePort.
A NodePort Service is created in Kubernetes by defining a Service resource with the type field set to NodePort. The Service will be assigned a cluster-internal IP address and a NodePort, which is a static port on each node in the cluster that is mapped to the Service's port. After writing the above service.yaml kubectl apply -f service.yaml this command will bind the cluster with an IP using the service.yaml configuration file.
Viewing the Cluster IP
$ kubectl get svc --namespace node-app-namespace this command will show the cluster IP and mapped port as below:
As we can see the cluster IP is now bound with port 8000 .
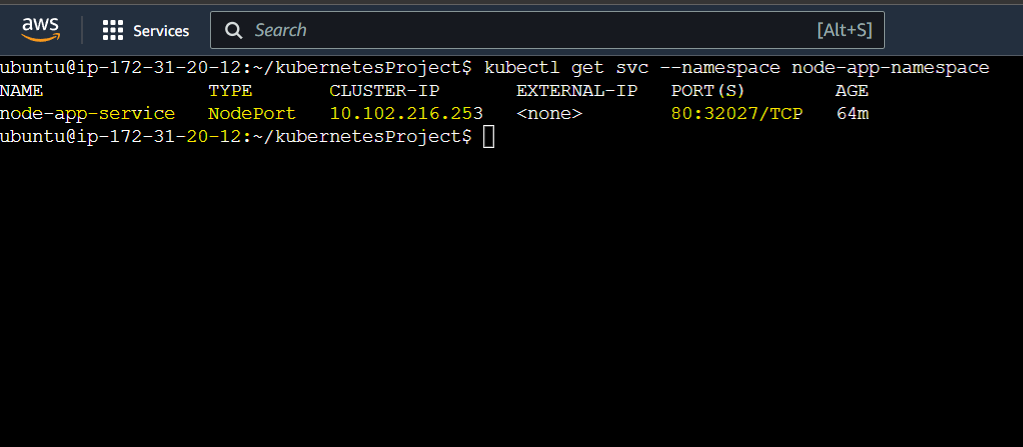
NB: this is the cluster IP not our EC2 instance IP so we can't yet use this IP to access from outside.
Getting the URL to access from an external browser
minikube service node-app-service -n node-app-namespace this command will give us the URL that we can use to see the page inside the local machine's browser.
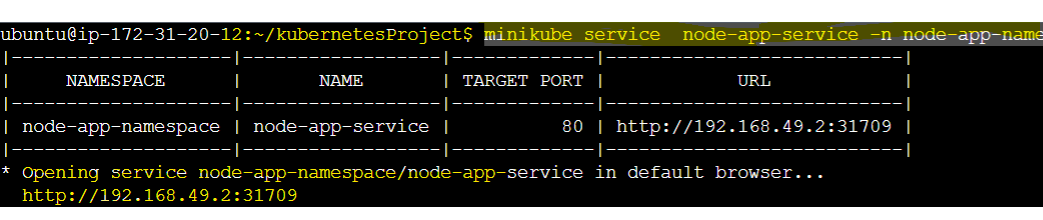
OR
minikube service node-app-service -n node-app-namespace --url can also give us the URL below:
Sending a curl request to the IP
After getting the IP we can then send a request from our machine with the command:
$ curl -L http://192.168.49.2:31709 which will be shown as below.
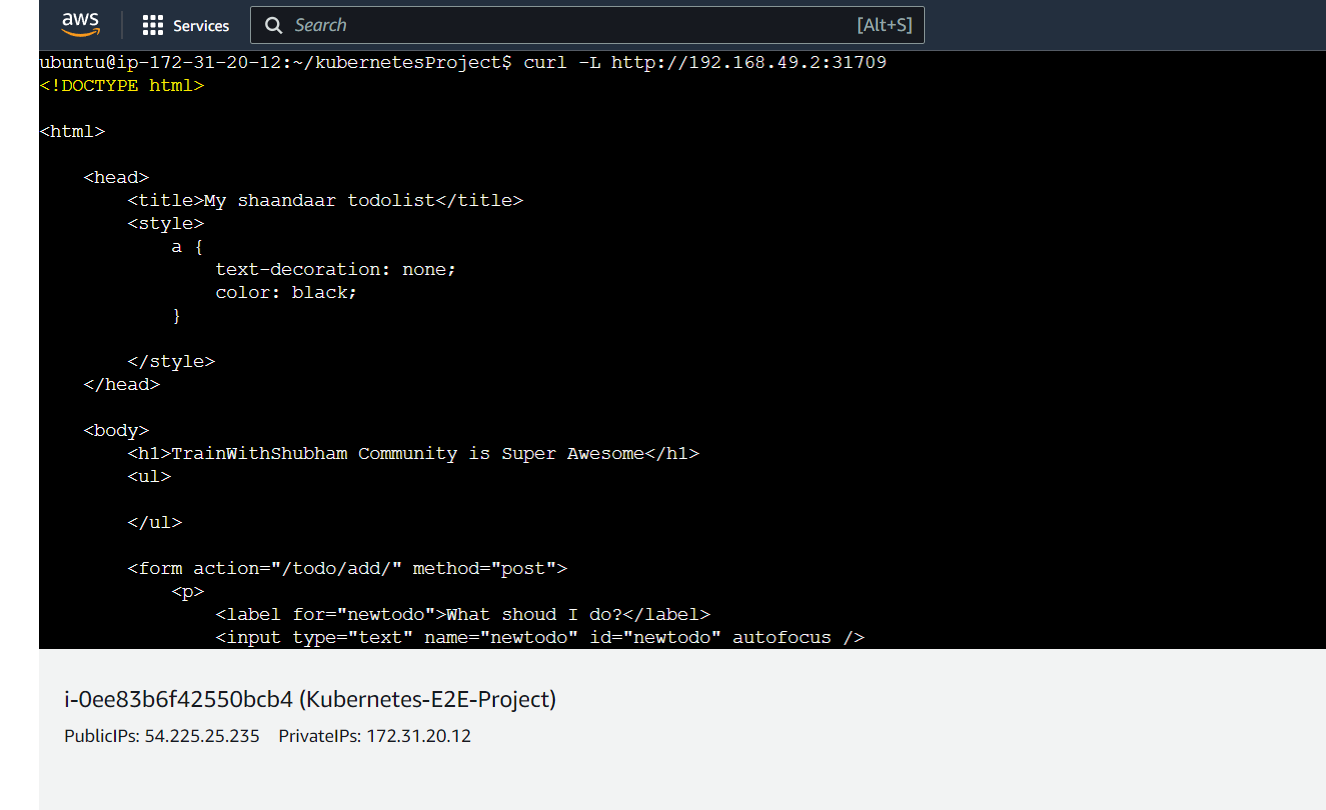
In the above picture, we are getting the HTML codes of the web page as we are accessing this EC2 instance from CLI only. There is no GUI involvement.
However, the connection is successful now.
Accessing it from Outside Browser using NGROK for Testing
Currently, our app is running inside the cluster and it is not accessible outside. To make it available to the outside we have a dependence on a tool called ngrok.
For more: https://dashboard.ngrok.com/get-started/setup
What is NGROK?
ngrok is a cross-platform application that enables developers to expose a local development server to the Internet with minimal effort. The software makes your locally-hosted web server appear to be hosted on a subdomain of ngrok.com, meaning that no public IP or domain name on the local machine is needed.
Step-1(Downloading NGROK)
$ wget https://bin.equinox.io/c/bNyj1mQVY4c/ngrok-v3-stable-linux-amd64.tgz
The above command will download the ngrock setup for Linux.

Step-1.2(Extracting ngrok)
$ tar -xvzf ngrok-v3-stable-linux-amd64.tgz
This is used to extract the package
Step-1.3(Installing the extracted file)
$ sudo snap install ngrok will install ngrok

Step-2(Authenticating yourself to connect to NGROK)
Before using ngrok we need to authenticate and generate a token for secure tunnel creation. You can do it from ngrok website by coping the below line.
**NB: "**2LER3tmAHlElRfZpBbUjUaBOuUn_7MwvX6U1fWmHg97Yhhyyd" this part will be different for your account.
$ ngrok config add-authtoken 2LER3tmAHlElRfZpBbUjUaBOuUn_7MwvX6U1fWmHg97Yhhyyd using this am now able to access as below:

Step-3(Establishing secure Tunnel)
After getting authenticated, we need to establish the tunnel using ngrok and our NodePort IP that we got using minikube service node-app-service -n node-app-namespace --url .
Step-4(Accessing the app from external browser)
ngrok http 192.168.49.2:32027 this command will now establish the secure tunnel as below and you can access the application from the browser using the selected URL against the Forwarding key.
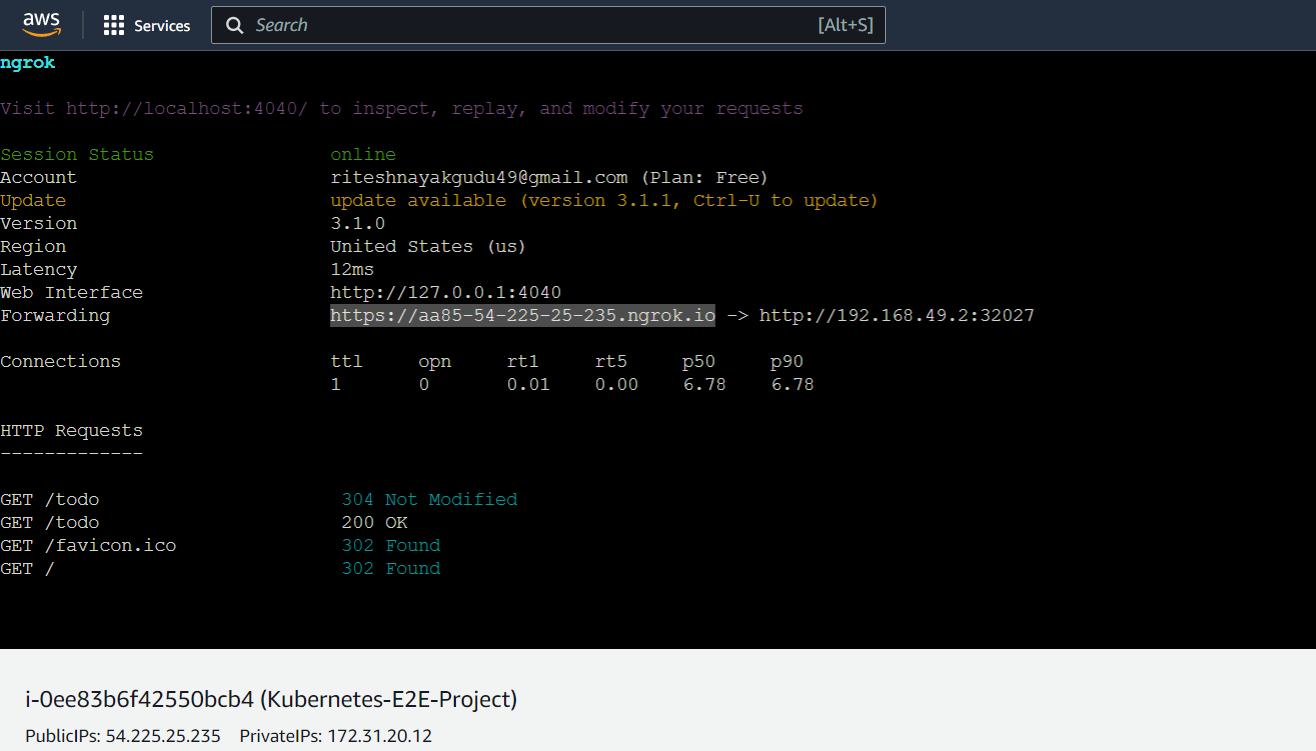
Finally, we can see the application below:
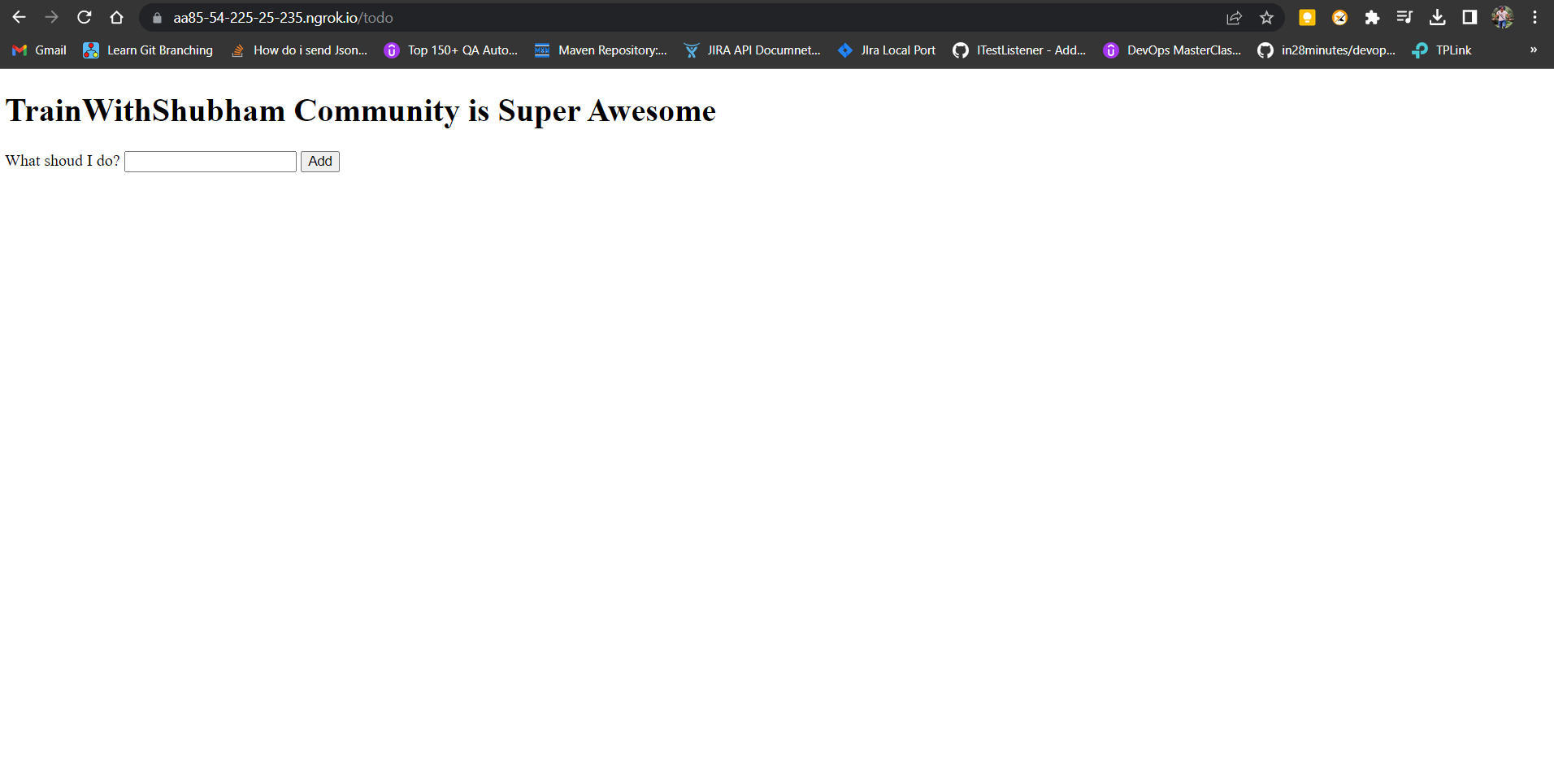
NB: In production, ngrok is not used. This is just for testing purposes.
Ingress
Ingress is a Kubernetes resource that provides a way to route incoming traffic to your Services based on the hostname or URL path. It acts as a reverse proxy for incoming HTTP or HTTPS traffic, forwarding requests to the appropriate backend Service based on the rules defined in the Ingress resource.
An Ingress resource is defined as a YAML file and consists of a set of rules that define how incoming requests should be handled. Each rule maps a hostname or URL path to a backend Service, and can also specify additional properties such as the backend Service port, SSL certificate, and TLS settings.
Ingress is a Kubernetes version of NGNIX
Step-1(Creating an Ingress File)
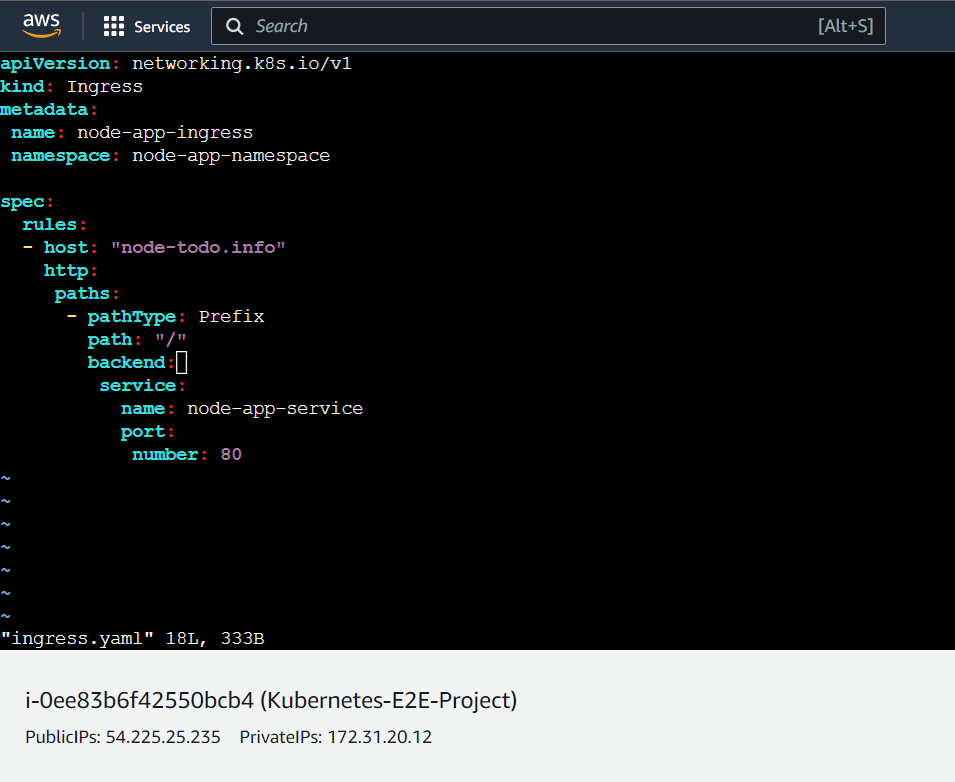
NB: -host: "node-todo.info" needs to be hosted on any hosting service like route53(AWS) , goDaddy etc.. However for now we will register this in our local(EC2 Ubuntu) server's host
Ingress provides a flexible and scalable way to manage incoming traffic to your application, allowing you to define different rules for different parts of your application, and to easily change the routing rules as your application evolves. It is typically used in combination with a LoadBalancer Service or a reverse proxy to handle external traffic, or with a ClusterIP Service to handle internal traffic within a cluster.
Step-2(Running the Ingress.yaml)
$ kubectl apply -f ingress.yaml this will run the ingress.yaml as usal.

Step-3(Binding the ClusterIP to Local IP)
sudo vim /etc/hosts inside this file we need to bind the IP as below:
192.168.49.2 node-todo.info and save it. Which will look like
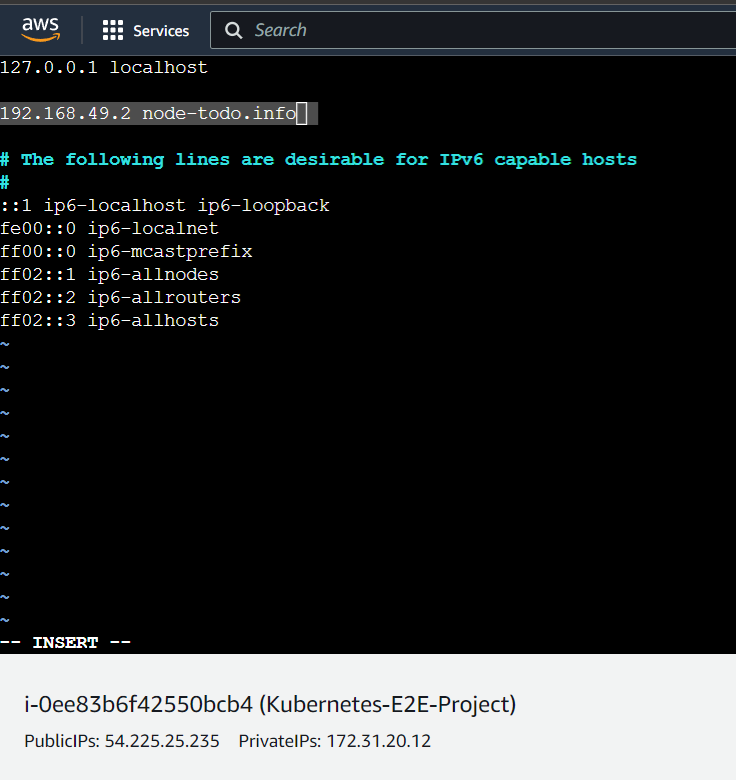
Above we have bounded the ip 192.168.49.2 to the hostname node-todo.info
In real-time, this will be done with some hosting service providers as discussed above.
Then we can save and apply.
use curl -L http://note-todo.info which will give the output as below: