Ansible E2E
Push-based & Pull-based, Ansible Vs Chef,Inventories, Playbooks, Multi-Environment Ansible, Loops in Ansible, Ansible tower, Ansible Vault

Passionate about helping organizations build scalable infrastructure and DevOps solutions with cloud technologies. Experienced in designing robust systems, automating processes, and driving efficiency through innovative cloud solutions. Advocate for best practices in DevOps and cloud computing, committed to enabling teams to achieve their full potential.
What is Ansible?
Configuration management (CM) is the practice of tracking and managing the changes that are made to a system's software, hardware, and documentation over time. This process is used to ensure that the system remains consistent and predictable, even as changes are made to it.
The primary goal of configuration management is to provide a systematic and disciplined approach to managing the configuration of a system. This involves identifying all of the components that make up the system, establishing baselines for those components, and then tracking changes to those components over time.
Effective configuration management is essential for ensuring that systems remain reliable, secure, and compliant with regulatory standards. It also helps to reduce the risk of errors and inconsistencies that can arise when changes are made to complex systems over time.
Alternatives of Ansible
Puppet: A configuration management tool that is designed to automate the management of software and system configurations.
Chef: A configuration management tool that uses a declarative approach to define and manage infrastructure as code.
SaltStack: An open-source configuration management and automation tool that is designed to manage large-scale systems.
How does Ansible Work?
Ansible uses a client-server architecture where the master node (server) manages the configuration of multiple managed nodes (clients).
The master node communicates with the managed nodes using SSH or WinRM protocols.
The inventory file contains the list of managed nodes and their details, such as the Username and IP address.
Playbooks are written in YAML format and define the desired state of the managed nodes.
Modules are small scripts that perform specific tasks on the managed nodes, such as installing software packages or configuring services.
Tasks are defined in playbooks and use modules to configure the managed nodes.
Roles are a collection of tasks, variables, and files that can be reused across multiple playbooks.
Ansible uses facts to gather information about the managed nodes, such as the operating system version and available memory.
Ansible uses SSH keys for authentication between the control node and managed nodes, allowing for secure communication.
Ansible can be extended through plugins, which allow for custom functions such as integrating with external systems or executing custom scripts.
There are two approaches to configuration management tools:
Push-Based Configuration Management
Pull-Based Configuration Management
Push-Based Configuration Management
Push-based configuration management tools are server-driven tools that push configurations from a central server to multiple client machines. In this approach, the server sends commands to the clients, telling them what to do and how to configure themselves.
This approach is useful in situations where administrators want to maintain a high level of control over the configurations of the client machines.
Example: Ansible
Pull-Based Configuration Management
Pull-based configuration management tools are client-driven tools that pull configuration information from a central server as needed. In this approach, the clients regularly check the server for updates through the agents installed in it and pull the latest configurations as required.
This approach is useful in situations where administrators want to allow more flexibility for the client machines and allow them to make some decisions about their configurations.
Example: Chef, Puppet
Ansible Vs Chef
Ansible is a simple, agentless, and open-source tool that uses YAML files to define the desired state of a system or infrastructure. It uses SSH to connect to remote hosts and execute commands or scripts. Ansible has a large and active community, and it is known for its ease of use, simplicity, and fast execution.
Chef, on the other hand, is an open-source configuration management tool that uses a declarative language called Ruby to describe the desired state of the system. Chef uses a client-server architecture and has a feature-rich interface that allows users to manage large and complex IT infrastructure environments. Chef also has a large and active community, and it is known for its flexibility, scalability, and powerful automation capabilities.
The choice between Ansible and Chef depends on the specific needs and requirements of the organization. Ansible is a great choice for small to medium-sized environments, and it is known for its simplicity and ease of use. Chef is a better choice for large and complex IT infrastructure environments, and it is known for its flexibility, scalability, and powerful automation capabilities.
Ansible Setup for Hands-on
To set up the Ansible server, ansible needs to be installed on the Master node which is nothing but a simple EC2 instance that can be Linux or Ubuntu or any other. As the client nodes will have to connect to the master node through SSH connection hence, a Public Key is needed for client servers just like we did with Jenkins to connect its Agent. To do so, we need to lunch an EC2 instance as usual keeping the SSH keys handy.
However, here we do not need to install ansible in every Client node, ansible only needs to be installed in the Master Server.
The Public Key will be given to all the Client nodes and the Private Key will be kept with the Master Node so that the master can connect to the clients using these keys through SSH.
Step-1(Ansible Installation)
Fetching the required files for Ansible:
NB: Ansible is based on Python hence, "ppa:ansible/ansible" is a library that contains all Ansible required dependencies and files.
$ sudo add-apt-repository --yes --update ppa:ansible/ansible
Installing Ansible from the files that are kept downloaded:
$ sudo apt install ansible
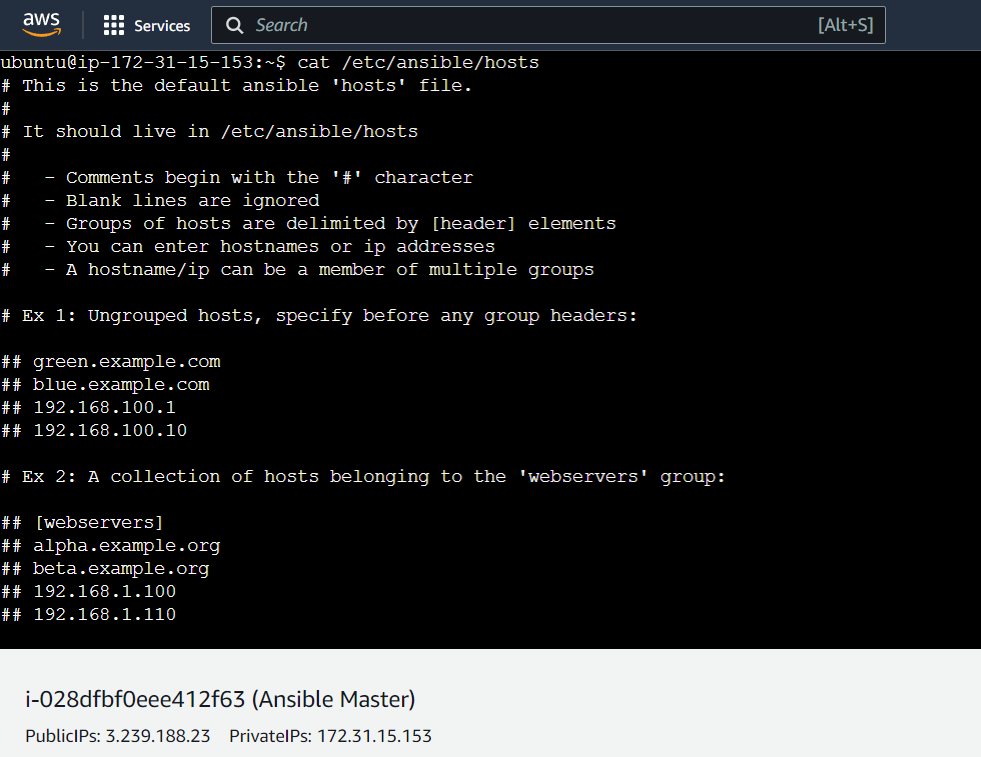
Checking the Inventory
cat /etc/ansible/hosts is the command that enables us to verify if ansible is properly installed by showing us the inventory file.
What is Inventory File?
In Ansible, an inventory is a configuration file that lists the target hosts or servers that Ansible can manage. It is essentially a list of hosts and groups that Ansible will use to execute tasks or playbooks. An inventory file can be a simple text file or a script that dynamically generates the inventory list based on some external data source, such as a cloud provider API or a database. The inventory file contains information such as the hostname, IP address, and connection type of the target hosts.
Which looks something like the below:
Step-2(Lunching Multiple Client Nodes)
So, to move forward with the setup, we need multiple servers to be launched which will be treated as Client Servers.
NB: While launching the instances make sure the key pair should be the same as the Master Node.
Here I have launched 3 Ubuntu instances. You can run any others as well such as Amazon Linux, MacOS or even windows.

Step-3(Adding Servers worker servers to Inventory File)
As we have already launched 3 additional servers, Ansible Master is not yet aware that it has to connect with which servers to perform configurations. As described above in the Inventory section, the master node where Ansible is installed contains a file called Inventory at the location /etc/ansible/hosts .
We have to add the Public IP of the Client nodes to let the master know about their presence. And to do so, we can simply edit the file with the nano editor sudo nano etc/ansible/hosts .
We have to add the below code snippets to the inventory file:
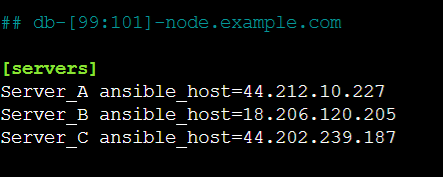
[Server]
Server_A ansible_host=54.81.233.56
Server_B ansible_host=54.234.32.97
Server_C ansible_host=54.167.112.95
The above piece of code is nothing but the Public IPs of the client servers which means that you're defining an Ansible inventory group named [Server] with three hosts: Server_A, Server_B, and Server_C. Each host is identified by its IP address using the ansible_host variable.
The ansible_host variable is used to specify the IP address or hostname of a remote host that Ansible should connect to. This variable is used to define the connection parameters for a host in an Ansible inventory file.
By default, Ansible will try to connect to the remote host using SSH and the default SSH port (port 22). If you need to connect to a remote host on a different port, you can specify the port number using the ansible_port variable.
Ansible Variables
Ansible has many other built-in variables just like ansible_host that you can use to customize your playbooks, roles, and tasks. Here are a few examples:
ansible_user: This variable specifies the username that Ansible should use to connect to a remote host. By default, Ansible will use the username of the current user running the playbook.ansible_port: This variable specifies the port number that Ansible should use to connect to a remote host over SSH. By default, Ansible uses port 22.ansible_ssh_private_key_file: This variable specifies the path to the private SSH key that Ansible should use to authenticate with a remote host. By default, Ansible will look for the SSH key in the current user's~/.ssh/directory.ansible_become: This variable specifies whether Ansible should run a task with elevated privileges (i.e., as the root user) usingsudoorsu. You can set this variable totrueto escalate privileges for a specific task.ansible_facts: This variable contains information about the remote host, such as its IP address, hostname, and operating system. You can use these facts in your playbooks to conditionally execute tasks based on the remote host's characteristics.
Step-4(Sending the private key file to the master node)
Copying the .pem file from local windows to EC2(Ansible-Master)
As we need to do SSH among the ansible nodes we need the Private key which is ansible_all_key.pem . This key needs to be present in the Master node because the master node will further establish an SSH connection to Ansible client nodes using this private key.
Currently the ansible_all_key.pem file is in my windows system and to send it to EC2 instance we need SCP request as below:
scp -i ansible_all_key.pem ansible_all_key.pem ubuntu@ec2-107-21-184-120.compute-1.amazonaws.com:/home/ubuntu/.ssh
Once the File is available in the Ansible Master server, give the file read write and execute permission so that it can be accessed when pinged else you will be getting an error as below where it says the access to the private key file is denied:

To give the permission use: chmod 600 ansible_all_key.pem
Step-5(Adding Server Variables to the inventory file)
[servers:vars]
ansible_python_interpreter=/usr/bin/python3
ansible_ssh_private_key_file=/home/ubuntu/.ssh/ansible_all_key.pem
We have defined some variables in an Ansible inventory file under the [Servers:vars] group.
Let me explain what each of the variables does:
ansible_python_interpreter: This variable specifies the path to the Python interpreter that Ansible should use on the remote host. In this case, Ansible will use the Python 3 interpreter located at/user/bin/python3.ansible_ssh_private_key_file: This variable specifies the path to the SSH private key file that Ansible should use to authenticate with the remote host. In this case, Ansible will use the private key file located at/home/ubuntu/.ssh/shellPractPutty.ppk.
Step-6(Connection Established)
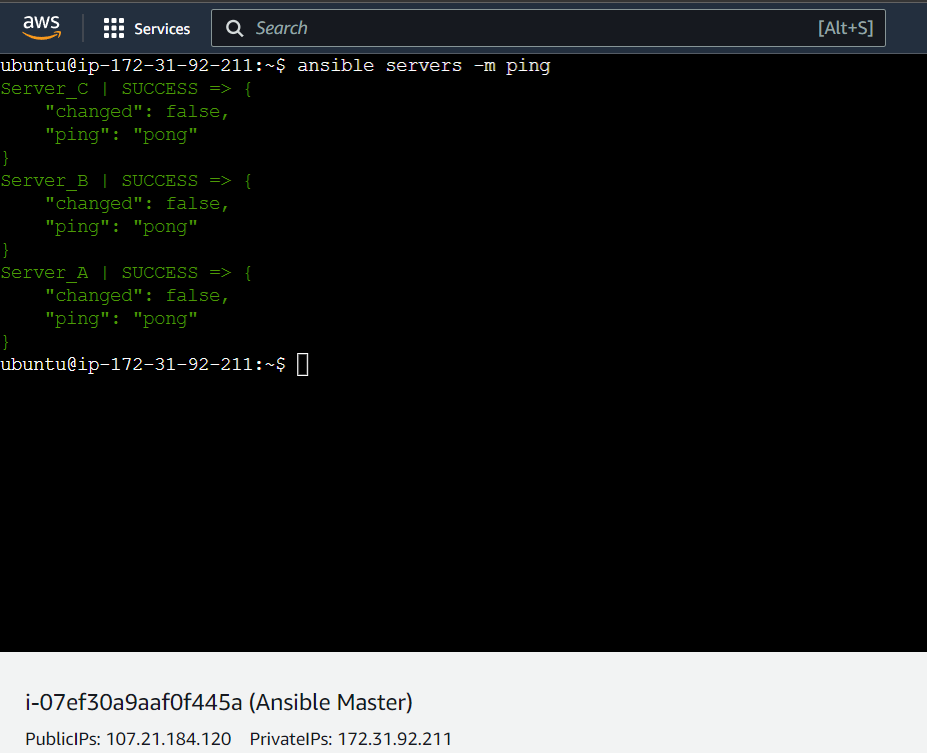
Once all the above steps are done flawlessly, you can ping all the servers mentioned in the inventory file using the command ansible servers -m ping
Here, the word servers can be anything depending upon the name you have defined in your inventory file while listing the server IPs. In my case, I have defined the name as servers. If I define it [web_servers] then the command should be ansible web_servers -m ping and so on:
Now the connection has successfully been established between the Ansible Master server and all other Client Servers:
We can perform several actions remotely on client servers right from the Ansible Master server.
Examples of some basics actions we can perform using ansible:
Below are just 3 basic examples but undoubtedly ansible is capable of a lot more:
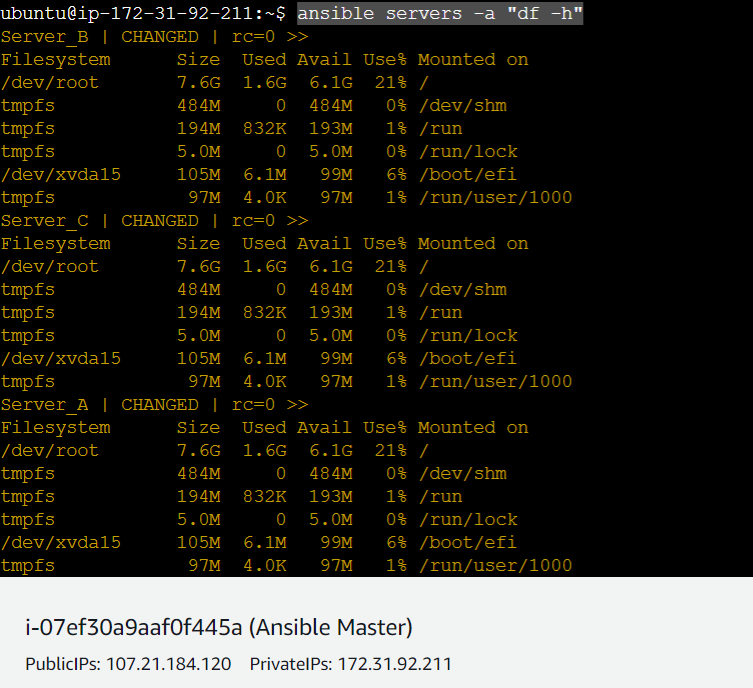
ansible servers -a "df -h"
The above command shows that executes the shell command "df -h" on all servers defined in the Ansible inventory file. More specifically, the command ansible servers tells Ansible to execute the command on all servers defined in the inventory file. The -a option specifies the command to execute, which in this case is "df -h". This command will display the disk usage statistics for each filesystem on the target servers in a human-readable format.
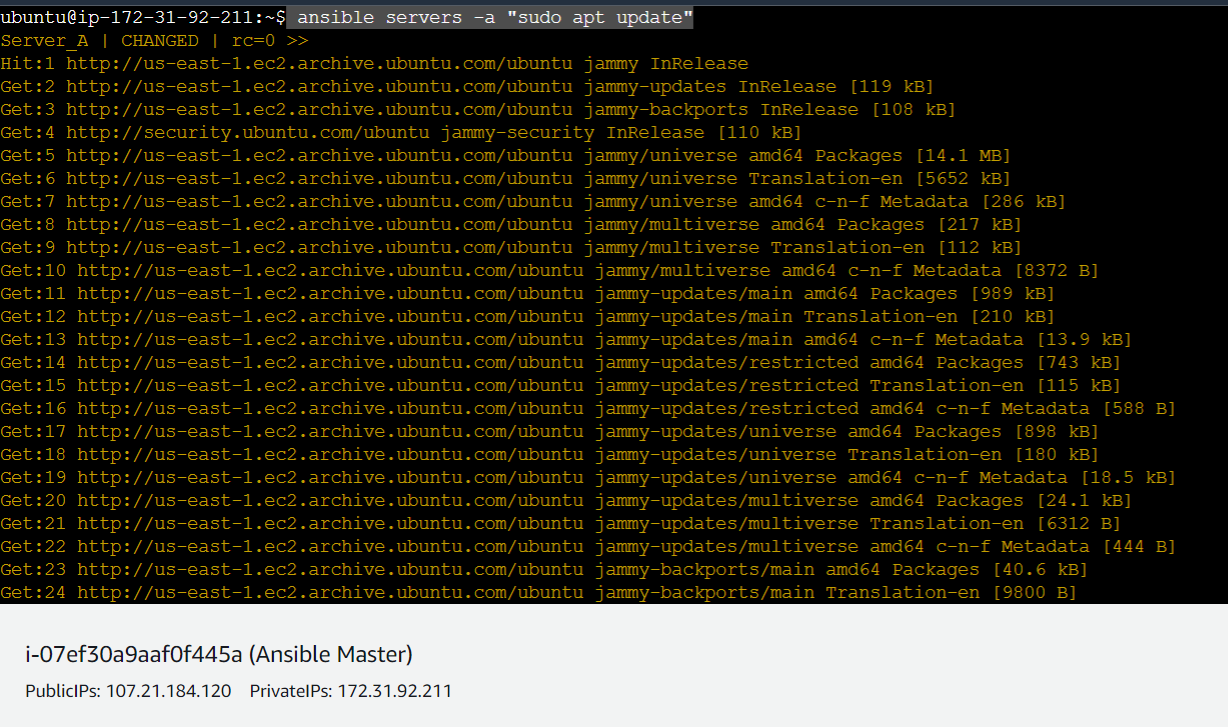
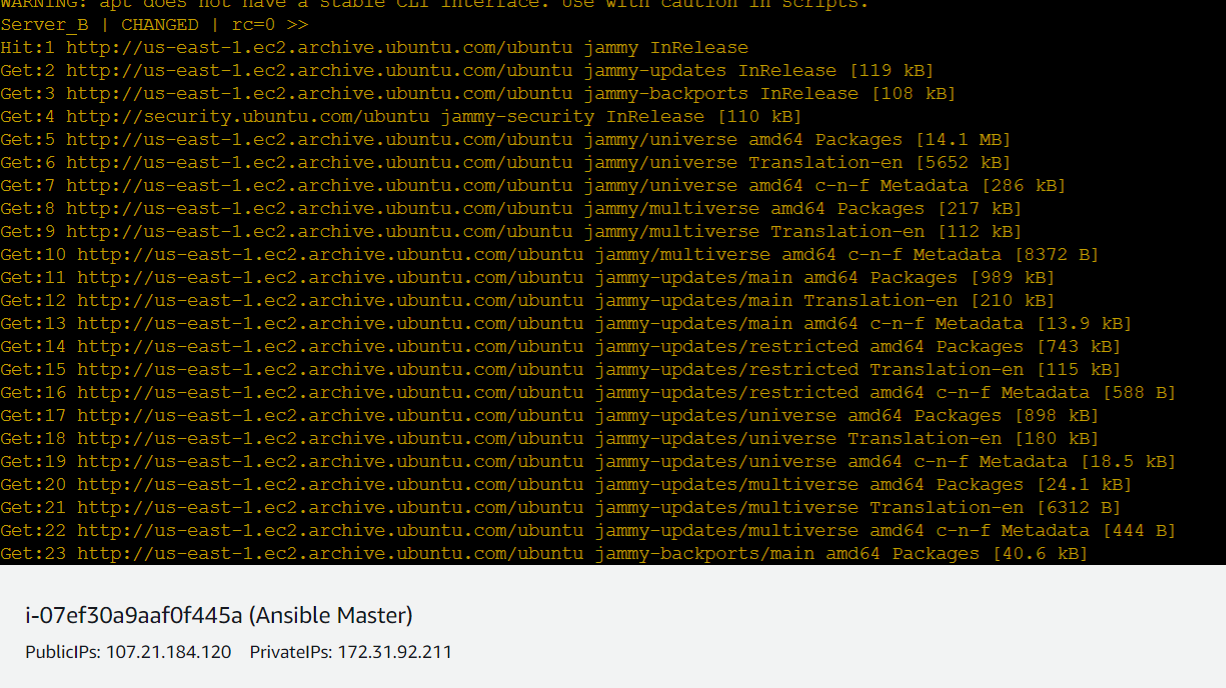
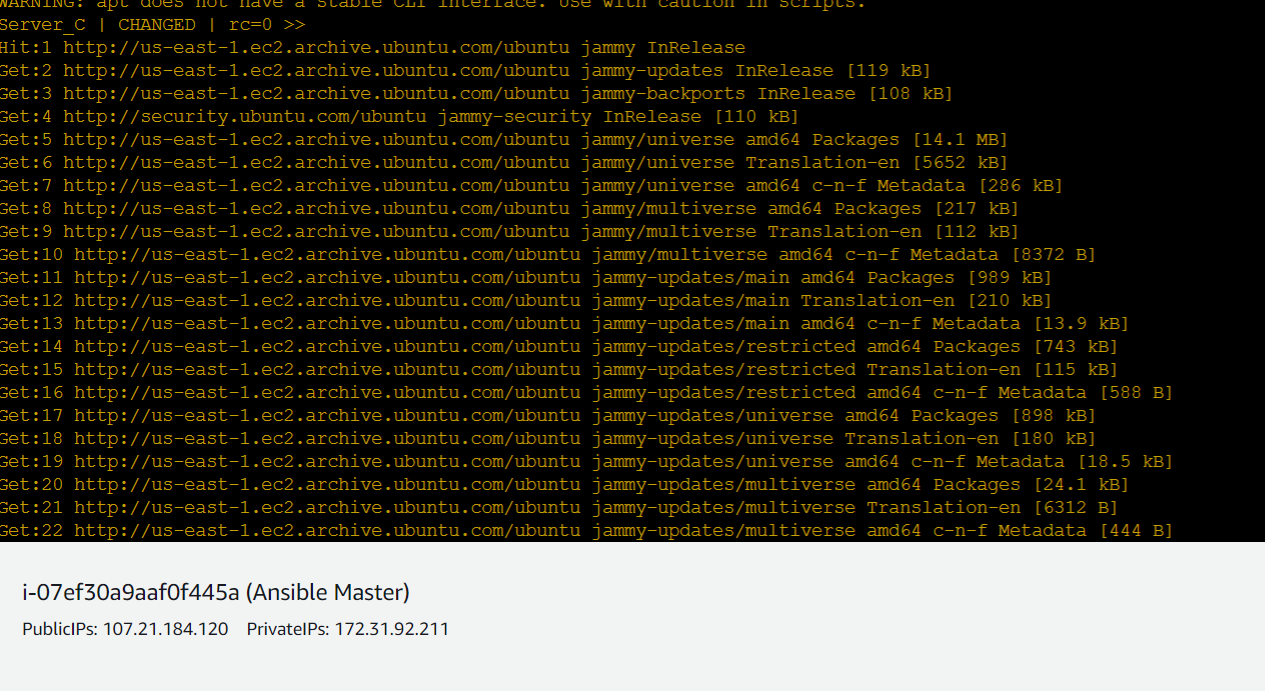
ansible servers -a "sudo apt update"
We can even update the servers remotely using the above command. Anything after the tag " -a " is considered as a specific command .
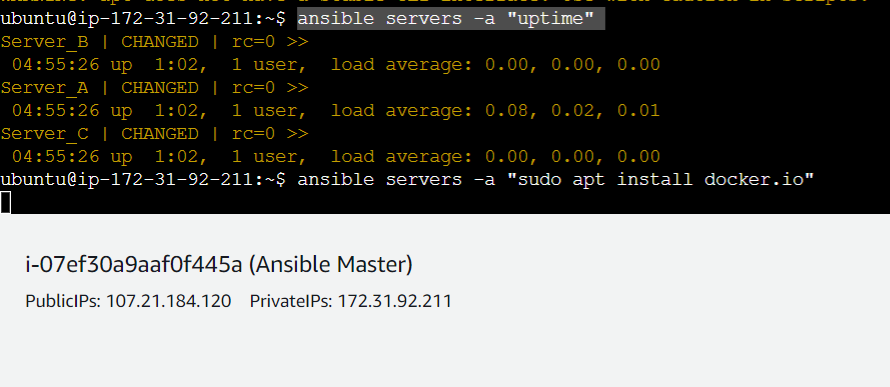
ansible servers -a "uptime"
This way we are checking the uptime of all the servers:
ansible servers -a VS ansible servers -m
Both ansible servers -a and ansible servers -m are Ansible command-line options that allow you to execute tasks on remote servers. However, they differ in the way they execute these tasks.
ansible servers -a is used to execute an ad-hoc command on the target servers. The -a option specifies the command to execute, which is typically a simple shell command like "df -h" or "ls". When you run an ad-hoc command with ansible servers -a, Ansible will SSH into each target server, run the specified command, and then exit. Ad-hoc commands are useful for quickly executing simple tasks on remote servers without the need for writing complex playbooks.
On the other hand, ansible servers -m is used to execute a module on the target servers. A module is a pre-defined Ansible task that performs a specific action, such as installing a package or managing a user account. The -m option specifies the name of the module to execute. When you run a module with ansible servers -m, Ansible will SSH into each target server, execute the module, and then exit. Modules are useful for executing more complex tasks that require specific functionality not available in ad-hoc commands.
In summary, ansible servers -a is used to execute simple shell commands on remote servers, while ansible servers -m is used to execute pre-defined Ansible modules on remote servers.
Multi-Environment Ansible Configuration
In real-time a DevOps engineer has to manage multiple environments such as DevQA, UAT, Staging and Production. Here, ansible plays a vital role in managing the configuration of several environments.
Previously we have configured all the servers in a single inventory file and there is nothing wrong with that. However, to make it more feasible and to interact with the servers individually DevOps engineers usually create multiple inventory files to manage multiple environments. Here we will see that by creating different inventories for our servers.
To do so let's create an inventory file named prod_inv :
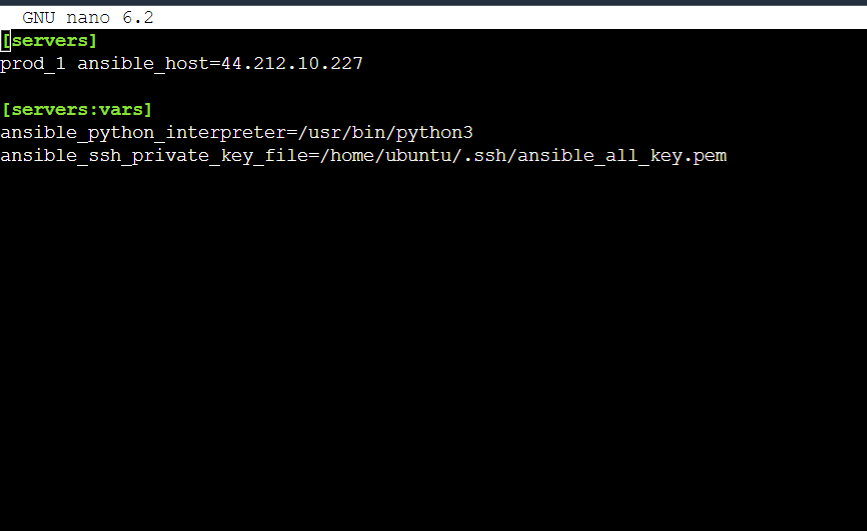
As you can see the above file contains only one server and that is grouped under [servers] and named prod_1 .
Connecting to the Server Iindividually
ansible -i prod_inv servers -m ping
The above command will use Ansible to execute the "ping" module on all servers defined in the "prod_inv" inventory file. The -i option specifies the inventory file to use, which in this case is "prod_inv". The -m option specifies the name of the module to execute, which is "ping" in this case.
When executed, the "ping" module will attempt to connect to each target server and return a successful response if the connection is established. This can be a useful way to quickly test the connectivity to a group of servers and ensure that Ansible can successfully connect to them.

Likewise, we can create another inventory named devQA_inv :
[servers]
devQA ansible_host=18.206.120.205
[servers:vars]
ansible_python_interpreter=/usr/bin/python3
ansible_ssh_private_key_file=/home/ubuntu/.ssh/ansible_all_key.pem
Ansible Playbook
Just like Docker has a docker file, Jenkins has a Jenkins file similarly Ansible has it's playbook. An ansible playbook is a collection of tasks that are defined in a YAML format and executed on a set of target hosts using Ansible. Playbooks allow you to automate complex tasks such as provisioning infrastructure, deploying applications, and managing configurations across multiple servers.
The tasks in a playbook are organized into plays, which are groups of tasks that are executed against a specific set of hosts. Each task in a playbook is a self-contained action that performs a specific function, such as installing a package or copying a file. Playbooks also allow you to define variables, templates, and handlers that can be reused across multiple tasks.
When executed, Ansible reads the playbook and performs each task in sequence, connecting to the target hosts over SSH and executing the appropriate commands to complete the task. Playbooks can also include conditional statements, loops, and other control structures that allow for more complex logic to be implemented.
Writing a Playbook
-
name: This playbook will install nginx
hosts: servers
become: yes
tasks:
- name: install nginx
apt:
name: nginx
state: latest
- name: start nginx
service:
name: nginx
state: started
enabled: yes
Playbook Explanation
This is an example of an Ansible playbook that installs and starts the Nginx web server on a group of servers defined in the inventory file under the name servers. Let's break down the playbook:
name: This is the name of the playbook, and it is purely for informational purposes.hosts: This is the group of servers that the playbook will be executed against. In this case, the playbook will be executed against the servers group defined in the inventory file.become: This is a special Ansible keyword that allows the playbook to run with elevated privileges on the target hosts. In this case, the playbook will run withsudoprivileges.tasks: This is a list of tasks that the playbook will execute on the target hosts.name: This is the name of the first task, which is to install Nginx.apt: This is an Ansible module that is used to manage packages on Debian/Ubuntu systems. In this case, it will install the latest version of thenginxpackage.name: This is the name of the package to install, which isnginxin this case.state: This is the desired state of the package, which islatestin this case.
name: This is the name of the second task, which is to start the Nginx service.service: This is an Ansible module that is used to manage system services.name: This is the name of the service to manage, which isnginxin this case.state: This is the desired state of the service, which isstartedin this case.enabled: This option ensures that thenginxservice is enabled to start automatically upon system reboot.
Overall, this playbook will install the latest version of the nginx package on all servers defined in the inventory file, start the nginx service, and ensure that it is configured to start automatically upon system reboot.
Playbook Execution
ansible-playbook install_nginx.yml
The above command will execute the playbook named install_nginx.yml. This is the name I have given to the above playbook. Once it is executed it looks like below:

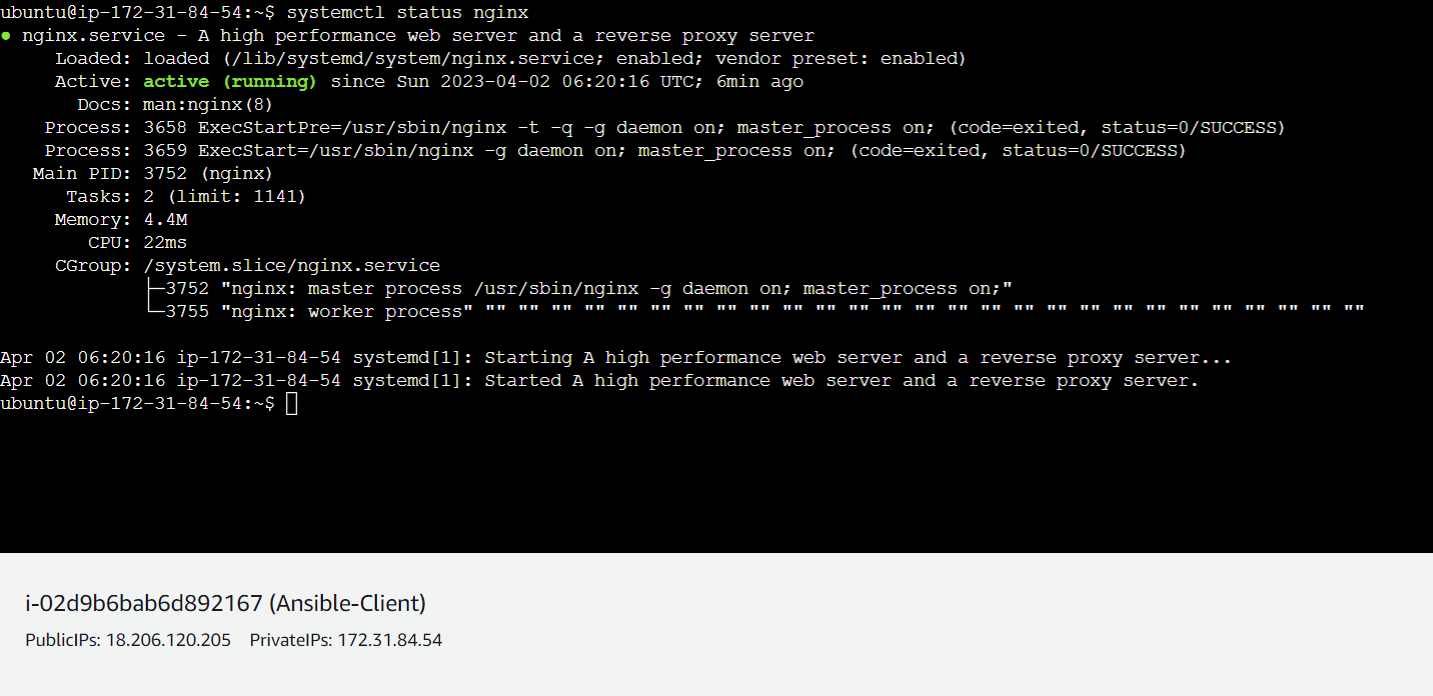
Verifying if the nginx server is successfully running :
Now let's connect to any of the 3 client servers to see if nginx is up and running by systemctl status nginx
Stopping any service from the playbook
To stop any service then change the state to "stopped" under service and run the playbook again.
service:
name: nginx
state: stopped
enabled: yes
Conditional Statements in Playbook
In an Ansible playbook, conditions are used to control the flow of execution based on certain conditions. The following are some of the commonly used conditions in Ansible:
when: This condition is used to control the execution of a task based on a certain condition. For example, you can use "when: ansible_os_family == 'RedHat'" to ensure that a task is executed only on RedHat-based systems.
failed_when: This condition is used to mark a task as failed based on a certain condition. For example, you can use "failed_when: result. stdout is not defined" to mark a task as failed if the stdout of the previous task is not defined.
changed_when: This condition is used to control the "changed" status of a task. For example, you can use "changed_when: false" to mark a task as unchanged even if it has been executed successfully.
ignore_errors: This condition is used to ignore errors that occur during the execution of a task. For example, you can use "ignore_errors: yes" to ignore errors and continue with the playbook execution.
until: This condition is used to repeat a task until a certain condition is met. For example, you can use "until: result.stdout == 'ready'" to repeat a task until the stdout of the previous task is "ready".
retries: This condition is used to retry a task a certain number of times if it fails. For example, you can use "retries: 3" to retry a task three times if it fails.
These conditions can be combined and used together to create complex control structures in Ansible playbooks.
Example of an Ansible Playbook with a Condition
-
name: This playbook will install docker based on OS distribution
hosts: servers
become: yes
tasks:
- name: install Docker
yum:
name: docker
state: latest
when: ansible_distribution == 'CentOS' or ansible_distribution == 'Red Hat Enterprise Linux'
- name: install aws cli
apt:
name: awscli
state: latest
when: ansible_distribution == 'Debian' or ansible_distribution == 'Ubuntu'
The first task named "install Docker" uses the "yum" module to install the docker with the package name "docker" and the state set to "latest" .
The second task named "install aws cli" uses the "apt" module to install the AWS CLI with the package name "awscli" and the state set to "latest".
In the above YAML file The "when" keyword is used to conditionally execute the task only when the distribution of the server matches either CentOS or Red Hat Enterprise Linux.
Overall, this playbook is a simple and effective way to install Docker and AWS CLI on servers running specific OS distributions.
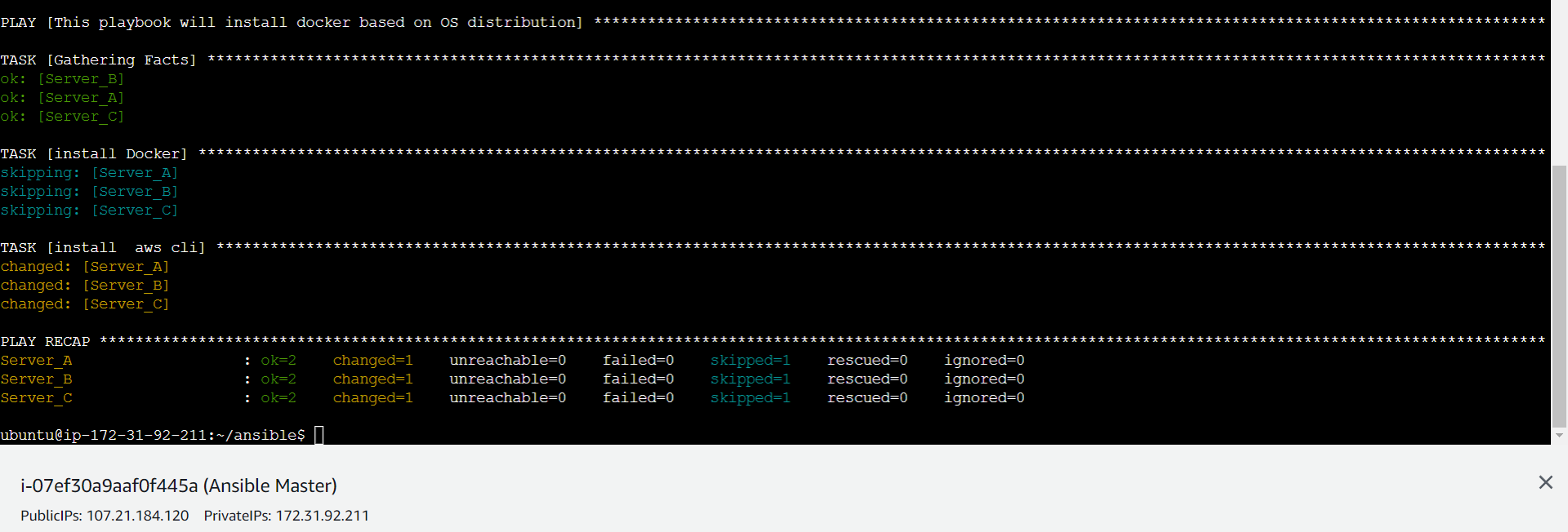
Now, when we use the command ansible-playbook install_docker_conditionally.yml
It shows the log below where the Docker installation task is getting Skipped and AWS CLI is being installed successfully because in the Playbook we have defined the condition as "only when the distribution of the server matches either CentOS or Red Hat Enterprise Linux " for Docker and "only when the distribution of the server matches either Debian or Ubuntu" for AWS CLI.
NB: install_docker_conditionally.yml is the file name where the above YAML codes are written.
Deploying a Static Web page using Ansible Playbook
Writing the Playbook for deployment:
- name: Deploy web application
hosts: servers
become: yes
tasks:
- name: install nginx
apt:
name: nginx
state: latest
- name: start nginx
service:
name: nginx
state: started
enabled: yes
- name: Deploy Webpage
copy:
src: index.html
dest: /var/www/html
Playbook Explanation
This is a complete playbook that can be used to deploy a simple static website using Nginx as the web server.
The playbook defines a single play named "Deploy web application" that targets the "servers" group of hosts. The become keyword is used to elevate the privileges of the user running the playbook to become a superuser.
The tasks section defines a list of tasks to be executed on the hosts. The first task installs Nginx using the apt module, which is a package manager for Debian-based systems.
The second task starts the Nginx service and enables it so that it starts automatically on system boot using the service module.
The final task deploys the index.html file to the web root directory using the copy module.
Overall, this playbook is a basic example of how to deploy a simple static website using Nginx as the web server.
Playbook Execution and Deployment on a Server named Prod:
ansible-playbook -i inventories/prod_inv webAppDeploy.yml
NB: Here webAppDeploy.yml is the name of the above playbook.
Once the playbook is completed we already have an inventory where we have defined servers we respective names. Our aim is to deploy the index.html page on that particular server through Ngnix.
The above command defines that the ansible-playbook will point to prod_inv and will deploy the web page using webAppDeploy.yml playbook.
Post Execution of webAppDeploy.yml
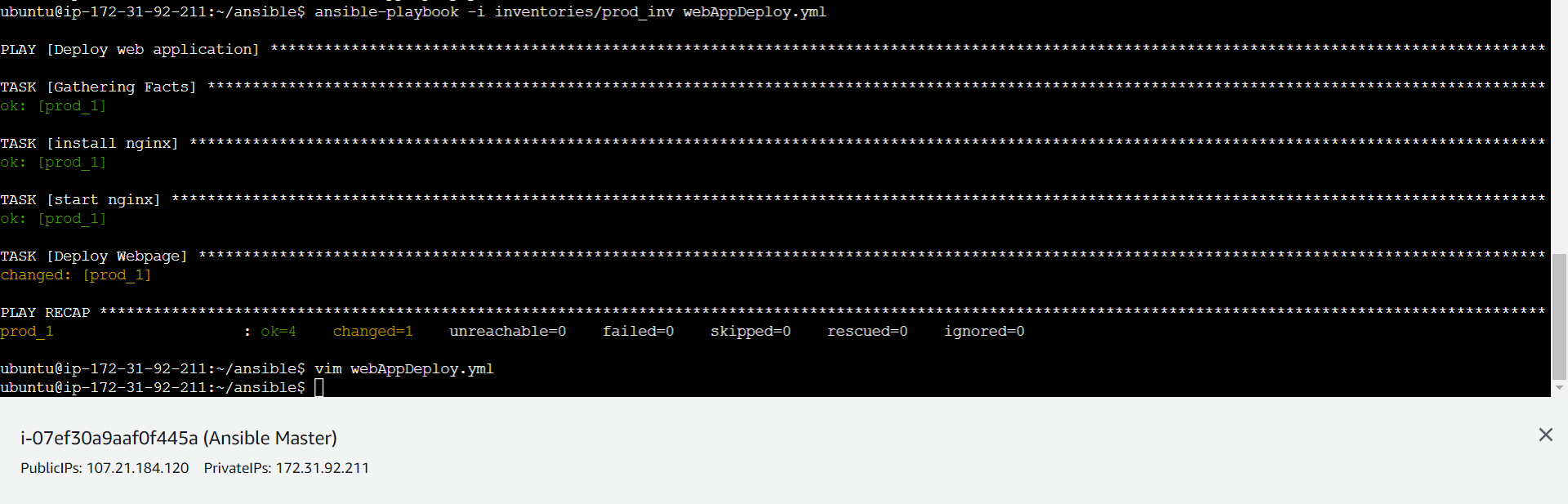
Now a static website using Nginx as the web server has been deployed.
Loops in Ansible
with_items is a loop control structure in Ansible that allows you to iterate over a list of items and perform a task or set of tasks for each item in the list.
To use with_items, you can include it in a task, and then provide a list of items for Ansible to iterate over. For example, the following task uses with_items to create multiple directories, one for each item in the directories list:
- name: create directories
file:
path: "{{ item }}"
state: directory
with_items:
- /var/www/html
- /var/log/nginx
- /etc/nginx/conf.d
In this example, Ansible will create three directories, one at each path listed in the directories list.
You can also use with_items with other modules to perform a task for each item in the list. For example, the following task uses with_items with the apt module to install multiple packages, one for each item in the packages list:
- name: install packages
apt:
name: "{{ item }}"
state: present
with_items:
- nginx
- mysql-server
- php
In this example, Ansible will install three packages, one for each item in the packages list.
Ansible Tower
Ansible Tower was originally developed by Ansible, Inc., which was later acquired by Red Hat in 2015. As a result, Ansible Tower is now owned and maintained by Red Hat, and is offered as part of the Red Hat Ansible Automation Platform.
Ansible Tower is an enterprise-grade platform for managing and scaling automation with Ansible. It provides a graphical user interface (GUI) and centralized management for deploying, managing, and monitoring automation workflows across an organization.
Ansible Tower enables teams to manage and orchestrate complex automation workflows and provides a unified view of automation across the enterprise. It allows teams to easily collaborate on automation projects, manage inventory and credentials and provides a powerful REST API for integrating with other systems.
Ansible Tower also includes features like job scheduling, notifications, and role-based access control (RBAC) to help teams automate with confidence and meet security and compliance requirements. Overall, Ansible Tower is a powerful tool for scaling automation with Ansible and streamlining DevOps processes in large organizations.
Ansible Vault
Ansible Vault is a feature in Ansible that allows you to encrypt sensitive data such as passwords, API keys, and other secrets, and store them securely in your playbooks or inventory files.
With Ansible Vault, you can encrypt entire files or individual variables, and decrypt them when running a playbook or inventory script. This allows you to keep sensitive data secure and separate from your codebase or version control system, while still allowing you to automate the deployment and configuration of your infrastructure and applications.
To use Ansible Vault, you create an encrypted file using the ansible-vault command-line tool, which prompts you for a password to encrypt the file. Once encrypted, you can edit the file using the same ansible-vault tool to add or modify the sensitive data.
When running a playbook or inventory script that contains an encrypted file, Ansible prompts you for the decryption password before running the script. This ensures that only authorized users with the correct password can access the sensitive data.
Overall, Ansible Vault is a powerful feature that allows you to automate the deployment and configuration of your infrastructure and applications while keeping sensitive data secure and separate from your codebase or version control system.